- Pascal's Chatbot Q&As
- Archive
- Page 25
Archive

An administration behaving like “rabid dogs”—officials who have shed the normative brakes of ideology, religion, or psychology, driven instead by a pathological hatred of adversaries...
...and a rejection of all ethical barriers. The “wishful thinking” that paralyzes the public, the “rational actor fallacy” that blinds the political class, and the “normalcy bias” that sedates media.


Allegation: Trump administration has repurposed and fused multiple government databases into a de facto “national citizenship data bank” and is pushing states to use it for mass “voter verification”.
When states match voter files against messy, repurposed federal data, U.S. citizens can get flagged as noncitizens and removed from rolls—or forced to jump through paperwork hoops to stay registered

PwC’s 29th Global CEO Survey: Executives are convinced AI is central to competitiveness, but most companies are still stuck in a “pilot-and-hope” phase where the economics don’t reliably show up.
Many companies are buying tools before they’ve built the operating conditions that make AI economically compounding (data access, workflow integration, governance, adoption, measurement).

How major technologies typically scale: not by “becoming evil,” but by being deployed inside incentive systems that already are.
If the default content diet becomes synthetic, low-cost, engagement-optimized media, you can get a slow-motion erosion of judgment, attention, and civic competence.

SDNY complaint (Atlantic/Warner/Sony/UMG entities + Spotify v. “Anna’s Archive” and Does 1–10) reads like a deliberate escalation: it’s not “just another piracy case,”
but a bid to treat mass scraping + DRM circumvention + imminent BitTorrent release as an existential threat to the streaming licensing stack.

ABP’s Palantir position—whether you see it as prudent exposure to a booming defense-tech contractor or as morally compromised capital—crystallizes the same global dilemma:
retirement security is increasingly financed through technologies that make states more capable of surveillance, coercion, and kinetic harm.

Where no human creative input is involved, copyright’s “originality” logic struggles, because originality in EU copyright doctrine is tied to human “free and creative choices” expressed in the work.
In practice, EU design registration can accommodate “AI output” as long as it meets design-law criteria. Even “low-creativity” processes can still yield protectable designs.
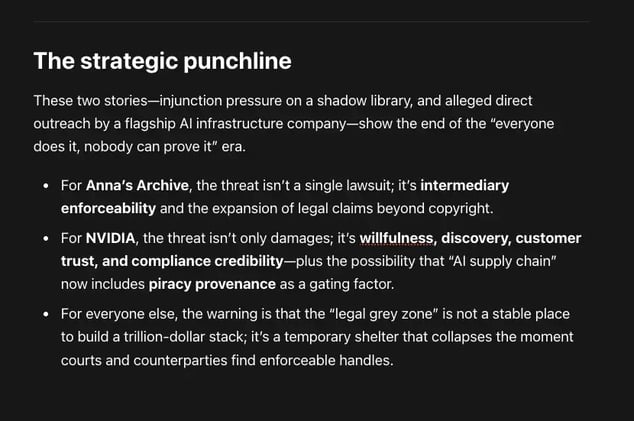
The plausible consequences for Anna’s Archive, NVIDIA, and any other AI developer that trained (directly or indirectly) on shadow libraries like LibGen, Sci-Hub, Z-Library, Books3, or The Pile.
When firms are credibly accused of using pirate corpora, licensing talks stop being “nice-to-have partnerships” and become risk buy-down.

X needs evidence that refusal to deal was truly concerted and notice campaign was not aggressive enforcement but systematically abusive and strategically targeted to suppress licensing competition.
If they can't, the practice of DMCA sending becomes defendants’ shield: Congress designed the mechanism; they used it; and antitrust shouldn’t rewrite copyright enforcement into compulsory licensing.

OpenAI is asking third-party contractors to upload “real assignments and tasks” from current or past jobs—ideally the actual deliverables.
An incentive structure that predictably pulls confidential work product into an AI lab’s orbit while delegating the hardest compliance judgments to the least protected people in the chain.
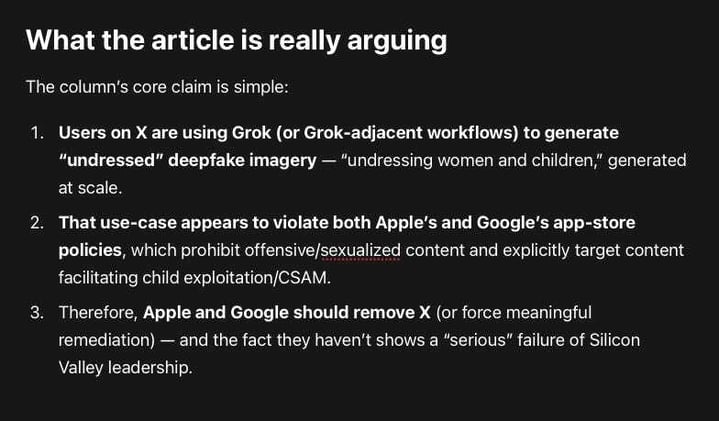
Apple and Google could act against X for facilitating nonconsensual sexual deepfakes (including content involving children), their own rules appear to demand action and yet they won’t because...
...the political and economic downside is too high. ChatGPT agrees with the article’s implication that the refusal to enforce app-store rules in the face of high-severity abuse is a leadership failure

A private investor platform can effectively set national tech priorities—especially in AI and defense—without public debate, parliamentary oversight, or enforceable transparency.
When informal political access becomes a competitive advantage, it erodes ethics norms, encourages a revolving-door ecosystem, and turns public staffing into an investable supply chain.