- Pascal's Chatbot Q&As
- Posts
- The plausible consequences for Anna’s Archive, NVIDIA, and any other AI developer that trained (directly or indirectly) on shadow libraries like LibGen, Sci-Hub, Z-Library, Books3, or The Pile.
The plausible consequences for Anna’s Archive, NVIDIA, and any other AI developer that trained (directly or indirectly) on shadow libraries like LibGen, Sci-Hub, Z-Library, Books3, or The Pile.
When firms are credibly accused of using pirate corpora, licensing talks stop being “nice-to-have partnerships” and become risk buy-down.
Pascal Hetzscholdt
January 20, 2026
When “Shadow Libraries” Meet Big Tech: The Anna’s Archive–NVIDIA Collision and Its Blast Radius
by ChatGPT-5.2
Two things happened almost at the same time, and together they crystallize where the “legal grey zone” around AI training is heading: (1) a U.S. federal court issued a default judgment and permanent injunction against Anna’s Archive tied to OCLC/WorldCat scraping, with OCLC signaling it intends to press intermediaries (hosts, registrars)to enforce it, and (2) reporting on an expanded authors’ class-action complaint alleges NVIDIA not only used shadow-library sourced books (Books3 et al.) but directly contacted Anna’s Archive to secure high-speed access to “millions of pirated materials,” despite being warned about illegality.
In our prior framing—AI firms “winning” by operating fast inside legal uncertainty—this is the moment the uncertainty starts to harden into enforceable chokepoints: contracts, infrastructure providers, and discovery trails.
Below are the plausible consequences—not just the obvious ones—for Anna’s Archive, NVIDIA, and any other AI developer that trained (directly or indirectly) on shadow libraries like LibGen, Sci-Hub, Z-Library, Books3, or The Pile.
1) Consequences for Anna’s Archive
A. Infrastructure strangulation gets easier (and more repeatable)
The injunction described is tailor-made for intermediary pressure: even if the operator is anonymous and judgment-proof, OCLC can present the order to hosting companies, CDNs, registrars, registries, payment rails, and other service providers and argue they risk being deemed “in active concert and participation” if they keep supporting distribution of the enjoined material.
Practical outcome: more domain suspensions / holds, more host churn, more reliance on mirrors, more operational friction. The TorrentFreak piece explicitly links the injunction to the likelihood of enforcement attempts against hosts/registrars and notes contemporaneous domain disruptions.
B. Legal theories expand beyond “copyright”
One of the most strategically important details is that the court granted relief based on trespass to chattels and breach of contract (browsewrap), not just classic copyright claims.
That matters because it:
Lowers the dependence on copyright’s slower, messier debates (e.g., “transformative” arguments).
Strengthens the playbook we’ve flagged before: “robots.txt is paper, not technical,” and courts increasingly treat scraping controls and ToS as legally meaningful boundaries even when technically bypassable.
Encourages more plaintiffs (publishers, databases, platforms) to sue shadow libraries via ToS + anti-scraping torts.
C. Forced deletion orders + “torrents included” creates enforcement hooks
The order reportedly requires deletion of WorldCat data, “including all torrents.”
Even if that’s ignored, it gives plaintiffs a perpetual lever to allege ongoing contempt-like behavior or to keep re-upping pressure on intermediaries: “they are still distributing enjoined datasets.”
D. Escalation to criminal exposure becomes likelier (even if not immediate)
Civil litigation like this creates documented fact patterns that can be re-used:
alleged daily scraping,
constructive notice of terms (browsewrap),
continued distribution after notice.
That doesn’t automatically become criminal, but it improves prosecutorial packaging if authorities ever choose to treat operators (or key facilitators) as more than civil defendants.
E. Reputation bifurcation: “public-good archivists” vs “industrial piracy”
Anna’s Archive has always lived on narrative warfare: access-to-knowledge rhetoric vs rights-holder enforcement. But when the public story becomes “selling high-speed access to AI companies,” the moral posture gets harder: it looks less like civil disobedience and more like commercial-scale trafficking in infringed goods.
Second-order effect: donors, volunteers, and sympathetic tech operators may become more cautious if the project is framed as an upstream vendor to trillion-dollar firms.
F. The “Streisand acceleration” risk
Ironically, high-profile enforcement can also increase awareness and mirror proliferation. TorrentFreak notes that revelations about contact with a major U.S. tech company could raise the shadow library’s profile further.
That can produce a whack-a-mole dynamic: more users, more mirrors, more decentralization—alongside harsher countermeasures.
2) Consequences for NVIDIA
A. Litigation risk jumps from “arguable” to “aggravated”
A core escalation in the reporting is the allegation that NVIDIA:
contacted Anna’s Archive to explore “high-speed access,”
was warned about illegal nature,
then got “the green light” to proceed anyway.
If proven, that pattern is exactly what plaintiffs use to argue willfulness, undercut good-faith narratives, and support:
statutory damages enhancement (where applicable),
broader injunctive relief,
and expanded theories like contributory/vicarious infringement.
B. Discovery spillover and internal governance exposure
The amended complaint reportedly cites internal NVIDIA emails and documents.
Once discovery is in play, risk isn’t only “did they train on X?” but:
who approved,
what compliance said,
whether warnings were overridden,
what vendors/contractors touched data,
and how models/datasets were documented.
This is the “management integrity” point we’ve pressed before: when leadership optimizes for velocity and demo deadlines, compliance doesn’t just lag—it becomes discoverable negligence.
C. Product and customer-contract consequences (indemnities, warranties, procurement bans)
Even absent a final judgment, large enterprise and government customers increasingly demand:
training-data provenance,
IP indemnities,
audit rights,
and representations about lawful sourcing.
If NVIDIA is perceived as having facilitated access to known pirate corpora, customers may:
demand stronger indemnities (raising cost/risk),
refuse certain models,
require retraining or exclusion of tainted components,
or route around NVIDIA tooling for regulated deployments.
D. Regulatory and policy blowback (especially on “data governance” claims)
A major strategic vulnerability is the mismatch between public “responsible AI” messaging and alleged sourcing from shadow libraries. That gap invites:
regulator interest (consumer protection / deception angles),
legislative scrutiny,
and reputational damage in standards bodies and procurement frameworks.
It also fuels the broader claim (which your Substack has articulated) that AI’s legal architecture is being built in grey zones that favor Big Tech—until courts and regulators catch up.
E. Model “taint” and remediation costs (the technical debt of illegality)
Even if a company wants to “clean” later, training contamination is not like deleting a file. Remediation can mean:
expensive retraining,
uncertain effectiveness of “machine unlearning,”
or restricting certain deployments and outputs.
That becomes a long-term balance sheet issue: legal risk becomes compute risk.
F. Expanded liability theories if tooling helped customers ingest pirated corpora
The reporting also references allegations that NVIDIA distributed scripts/tools enabling customers to download The Pile (containing Books3), supporting claims of contributory/vicarious infringement tied to revenue from facilitating access.
If this sticks, the exposure widens from “our internal training” to “we enabled an ecosystem.”
G. Capital markets and leadership risk
For a company whose valuation rests on trust in its role as infrastructure of the AI economy, the optics matter:
“we sell the shovels” is safer than “we also ran the heist.”
If the narrative becomes willful infringement plus cover-by-ambiguity, leadership faces:shareholder suits,
governance activism,
board-level compliance restructuring,
and executive accountability dynamics.
3) Consequences for any AI developer that used shadow libraries (directly or indirectly)
A. Shadow libraries become legally radioactive as sources, not just “datasets”
The moment “Anna’s Archive,” “LibGen,” “Sci-Hub,” “Z-Library,” and “Books3” are pleaded as specific upstream sources, they become easier for courts, regulators, and counterparties to treat as bright-line red flags—not fuzzy internet background noise.
B. More suits will copy the best fact patterns
Plaintiffs learn fast. If the browsewrap + trespass logic works against a shadow library in one context, others will re-use it.
If “warned about illegality, proceeded anyway” resonates against NVIDIA, others will hunt for similar emails elsewhere.
C. Industry-wide shift from “fair use debate” to “compliance audit economy”
We’ve been mapping this direction already: the center of gravity moves toward:
dataset registries,
provenance attestations,
standardized licensing pathways,
and evidence-grade documentation.
Not because companies suddenly get ethical—because procurement and litigation make it existential.
D. Rights-holders gain leverage in negotiations
When firms are credibly accused of using pirate corpora, licensing talks stop being “nice-to-have partnerships” and become risk buy-down. That’s where publishers can insist on:
audit rights,
downstream controls,
attribution/traceability,
and enforceable usage boundaries—precisely the governance infrastructure you’ve been pushing in other threads.
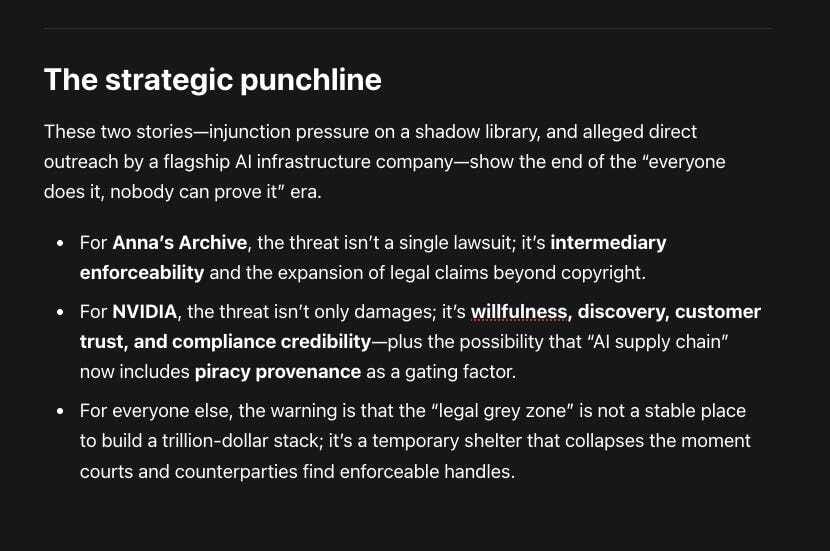
The strategic punchline
These two stories—injunction pressure on a shadow library, and alleged direct outreach by a flagship AI infrastructure company—show the end of the “everyone does it, nobody can prove it” era.
For Anna’s Archive, the threat isn’t a single lawsuit; it’s intermediary enforceability and the expansion of legal claims beyond copyright.
For NVIDIA, the threat isn’t only damages; it’s willfulness, discovery, customer trust, and compliance credibility—plus the possibility that “AI supply chain” now includes piracy provenance as a gating factor.
For everyone else, the warning is that the “legal grey zone” is not a stable place to build a trillion-dollar stack; it’s a temporary shelter that collapses the moment courts and counterparties find enforceable handles.
·
5 AUGUST 2024

Question 1 of 3 for ChatGPT-4o: Please read the news article "Leaked Documents Show Nvidia Scraping ‘A Human Lifetime’ of Videos Per Day to Train AI" and tell me what it says
·
21 JUNE 2025

YouTube, AI, and the Ethics of Consent — Google’s Gemini and Veo 3 Under Scrutiny
·
5 MARCH 2025

Asking ChatGPT-4o: Please read the “Report on Pirated Content Used in the Training of Generative AI” and the associated LinkedIn post and tell me what the key messages are and how AI makers should be responding to these issues.
·
14 APRIL 2025

Asking AI Services: Please analyze the press release and Amicus Brief of the Association of American Publishers in relation to the META AI Case and tell me whether or not you agree with their views.
·
14 APRIL 2025

Asking AI services: Please analyze the TorrentFreak article “Meta AI ‘Piracy’ Lawsuit: Publishers and Professors Challenge Fair Use Defense” and the associated Amicus Brief from the International Association of Scientific, Technical and Medical Publishers
·
7 FEBRUARY 2025

Asking AI Services: Please read the articles "“Torrenting from a corporate laptop doesn’t feel right”: Meta emails unsealed" and "‘Meta Torrented over 81 TB of Data Through Anna’s Archive, Despite Few Seeders’" and explain what happened, whether this is bad behaviour or not and what a) the judge should do and b) what the AI maker(s) should do to prevent…
·
5 JANUARY 2024
Question 1 of 4 for Google Bard: Please analyze the TorrentFreak article "Silenzio! ‘Anna’s Archive’ Shadow Library Blocked Following Publishers’ Complaint" and tell me what it says.