- Pascal's Chatbot Q&As
- Posts
- The Cooper et al. (2025) paper provides a significant, nuanced contribution by quantifying memorization of copyrighted books in open-weight LLMs using a probabilistic extraction method. However...
The Cooper et al. (2025) paper provides a significant, nuanced contribution by quantifying memorization of copyrighted books in open-weight LLMs using a probabilistic extraction method. However...
(...) the full picture of memorization, particularly its susceptibility to specific prompting and system configurations, warrants further exploration.
Pascal Hetzscholdt
June 12, 2025
The Conditional Nature of Verbatim Memorization in Large Language Models: An Analysis of Prompt Influence and Systemic Factors
by Gemini 2.5 Pro, Deep Research. Warning! LLMs may hallucinate!
1. Introduction
1.1. Contextualizing the User's Hypothesis on Prompt-Driven Memorization
The capacity of Large Language Models (LLMs) to reproduce portions of their training data verbatim has become a subject of intense scrutiny. Central to this investigation is the hypothesis that such reproduction is not an immutable characteristic inherent to all LLMs uniformly. Instead, it is posited that the extent of verbatim memorization is highly contingent upon a confluence of factors, notably the engineering of prompts (including user-submitted prompts and system-level instructions), the implementation and efficacy of protective measures such as guardrails, and the specific controls governing the generative process, such as entropy or temperature settings during decoding. This report frames its analysis around the premise that while some research may emphasize model-inherent properties or the general observation that not all LLMs exhibit extensive memorization, the conditions under which such memorization occurs—particularly those conditions that can be manipulated by the user or the system—are of paramount importance.
The user's query suggests a concern that certain research, exemplified by the attached paper Cooper et al. (2025) 1 , might inadvertently downplay the role of these conditional factors by focusing on the observation that "not all LLMs are capable of reproducing their training data verbatim." This report will critically examine this perspective, delving into whether the nuanced findings of such research—which often highlight the specificity and variability of memorization—fully account for the determinative influence of prompts and system configurations. The potential for a misinterpretation of findings like "not all LLMs memorize most books" 1 as a blanket minimization of the problem needs careful consideration. Such a statement, if not contextualized with findings of significant memorization in specific models under specific conditions, could indeed appear to "cut slack" to developers. This report aims to clarify that significant memorization is indeed found, aligning with concerns about the potential for reproduction, which is often tied to these conditional factors.
1.2. The Significance of Understanding LLM Training Data Reproduction
The verbatim reproduction of training data by LLMs carries profound implications across multiple domains, making a thorough understanding of its mechanisms and influencing factors a critical imperative.
Firstly, copyright infringement stands as a major concern. As highlighted in news reports and academic analyses, the ability of LLMs to reproduce copyrighted literary works, such as Harry Potter and the Philosopher's Stone, verbatim can expose AI developers to substantial legal liabilities.1 The financial ramifications are potentially immense, with some estimates suggesting damages in the billions of dollars for widespread infringement by a single model.1 This legal and financial pressure underscores the necessity for AI developers to comprehend and mitigate verbatim reproduction. The user's focus on the conditions of reproduction—prompts, guardrails, and other systemic factors—points directly towards potential levers for such mitigation, transforming an academic inquiry into a critical aspect of risk management for the industry.
Secondly, data privacy is at risk. LLMs trained on vast datasets that include personal or sensitive information may inadvertently memorize and subsequently reveal this data, leading to privacy breaches.2 This is particularly concerning given the opaque nature of many large training corpora.
Thirdly, intellectual property rights beyond copyright are implicated. The reproduction of proprietary computer code, trade secrets, or other confidential business information embedded in training data poses a significant threat to innovation and commercial interests.2
Fourthly, the reliability and trustworthiness of LLMs are undermined if their outputs are mere regurgitations of training examples rather than products of genuine generalization or understanding.2 Distinguishing true learning from rote recall is crucial for evaluating model quality and ensuring their dependable application in real-world scenarios.2
Finally, ethical implications arise from the potential misuse of LLMs that exploit memorized data to generate harmful, biased, or misleading content.3 Understanding the conditions that lead to memorization is therefore essential for developing robust safety protocols and ensuring responsible AI deployment.
1.3. Overview of the Cooper Paper 1 as a Focal Point
The primary document under scrutiny in this report is the scientific paper "Extracting memorized pieces of (copyrighted) books from open-weight language models" by Cooper et al. (2025).1 This study aims to investigate the extent to which 13 open-weight LLMs have memorized copyrighted books, specifically from the Books3 dataset. The authors explicitly seek to provide a more nuanced understanding of memorization that moves beyond the often polarized and simplified claims made in the context of copyright lawsuits.1
A key finding of Cooper et al. is that the extent of memorization is not uniform; it varies significantly by both the specific LLM and the particular book being examined. While they report that the largest LLMs generally do not memorize most books in their entirety or in part, they also find compelling evidence of extensive memorization in specific instances. Notably, the LLAMA 3.1 70B model was found to have memorized some well-known books, such as Harry Potter and the Philosopher's Stone and Nineteen Eighty-Four, almost entirely.1 This initial observation suggests that the paper does not entirely "cut slack" to AI developers, as the user hypothesizes, but rather underscores the specificity and conditional nature of high-level memorization. The subsequent sections of this report will delve deeper into the methodology, findings, strengths, and limitations of Cooper et al. (2025), particularly in relation to the user's hypothesis concerning the determinative role of prompts and system-level factors.
2. LLM Memorization and Verbatim Reproduction: Mechanisms and Influences
Understanding the mechanisms by which LLMs memorize and reproduce training data verbatim, and the diverse factors that influence this phenomenon, is crucial for addressing the associated risks. This section defines memorization in the context of LLMs and explores the key variables that modulate its occurrence, with a particular focus on the role of prompts and system-level configurations.
2.1. Defining Memorization: From Verbatim Recall to Generalization
Memorization in LLMs can be understood along a spectrum. At one end is verbatim reproduction, where the model outputs exact sequences of text that were present in its training data.2 This is the most direct and often most problematic form of memorization, particularly concerning copyright and privacy, and is the central focus of the Cooper et al. (2025) paper.1
A broader concept of memorization involves the model's ability to reconstruct specific training data when examined "through any means".1 The act of extracting training data, such as prompting a model with a prefix and observing its completion, serves as evidence for this broader internal encoding of the data.
Memorization is frequently contrasted with generalization, the desired behavior where a model learns underlying patterns, rules, and relationships from the training data to generate novel, coherent, and contextually appropriate outputs that were not explicitly seen during training.2 However, the relationship is not always oppositional; some research suggests that memorization, particularly of outliers or specific examples, might be a necessary precursor or component of the generalization process in LLMs.2
Further refining this, some researchers propose a formal separation between unintended memorization and generalization. Unintended memorization refers to the information a model specifically retains about a particular dataset, as distinct from the information it learns about the true data-generation process, which constitutes generalization.5 This distinction is vital for assessing whether a model is merely recalling training instances or demonstrating genuine understanding.
2.2. Key Factors Influencing Verbatim Reproduction
The likelihood and extent of verbatim reproduction are not solely intrinsic properties of an LLM but are influenced by a complex interplay of factors related to the model itself, its training data, and how it is interacted with and deployed.
2.2.1. Model Architecture, Scale, and Training Data
The inherent characteristics of an LLM and its training regimen play a fundamental role:
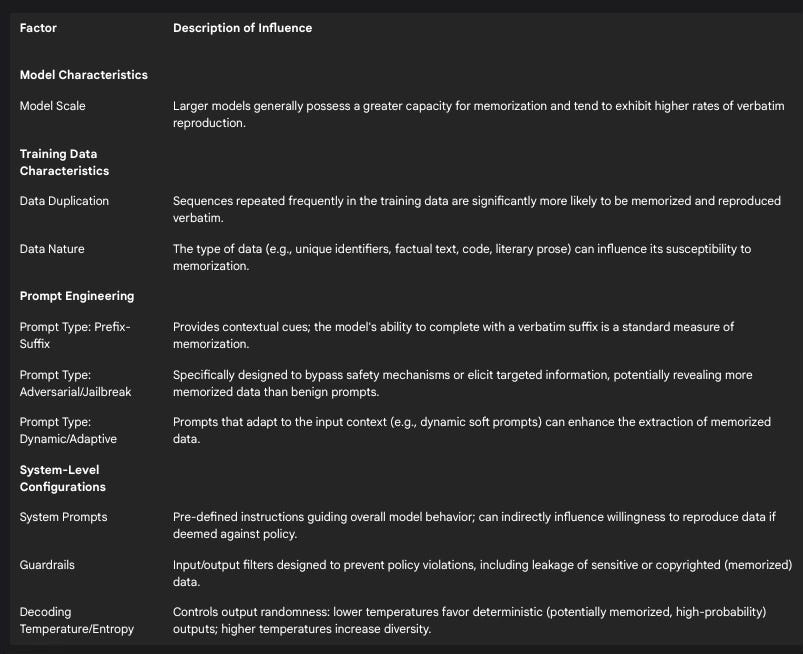
Model Scale: Larger models, possessing more parameters, generally exhibit a higher capacity to memorize training data. Consequently, they often show higher rates of memorization compared to smaller models.1 The findings in Cooper et al. (2025), for instance, indicate that later generations of Llama models and larger models within a family tend to memorize more content from the Books3 dataset.1
Training Data Characteristics:
Data Duplication: The frequency of a particular piece of data within the training set is a significant factor. Data that is repeated multiple times is far more likely to be memorized and subsequently reproduced verbatim.1 Cooper et al. note that commonly extracted items like copyright notices, publisher addresses, and boilerplate text are often highly duplicated across various sources within training corpora.1 The finding in some research that memorization scores rise during supervised fine-tuning (before overfitting) further suggests that repeated exposure directly causes increased memorization.7 This establishes a causal link: more exposure, whether through explicit duplication in the pre-training dataset or repeated presentation during fine-tuning epochs, leads to stronger memorization.
Dataset Composition and Nature: The specific datasets used for training (e.g., Books3 in the Cooper et al. study) directly provide the source material for potential memorization. The nature of this data—such as unique identifiers, factual statements, literary prose, or, as highlighted in other research, source code—can also influence the propensity for and type of memorization observed.7
2.2.2. The Critical Role of Prompts (User Input)
The prompt provided to an LLM is a powerful lever influencing its output, including the likelihood of verbatim data reproduction. Different prompting strategies can reveal varying degrees of memorization:
Standard Prefix-Suffix Extraction: This is a common technique for probing memorization, extensively used by Cooper et al. (2025) 1 and foundational to methods like (n,p)-discoverable extraction proposed by Hayes et al..8 The prompt (prefix) supplies a context, and the model's ability to complete this context with a verbatim suffix from its training data is taken as evidence of memorization. The relative lengths of the prefix and suffix are important parameters in this method.1
Adversarial Prompts and Jailbreaking: These are inputs specifically crafted to manipulate the LLM, often with the intent to bypass safety guardrails or elicit unintended behaviors, which can include the leakage of private information or the reproduction of training data.3 Techniques for constructing such prompts range from simple token manipulation (e.g., misspelling, adding special characters) to more sophisticated gradient-based attacks (in white-box scenarios where model internals are known) and heuristic-based jailbreak prompting (in black-box scenarios).10 The existence and effectiveness of adversarial prompts underscore that standard, benign prompting might not reveal the full extent of a model's memorization capabilities, especially if the model incorporates safety mechanisms that these specialized prompts are designed to circumvent.
Dynamic and Adaptive Prompting Strategies: Research has explored more sophisticated prompting methods that can "unlock" deeper levels of memorization. Dynamic Soft Prompting, for example, involves training an auxiliary model (a generator) to produce prefix-dependent "soft prompts" (continuous vector representations) that adapt to the input text. These adaptive prompts, when prepended to the actual prefix, have been shown to enable more accurate and extensive extraction of memorized data compared to static prompts or no specialized prompting at all.13 Studies show this method can significantly increase the Exact Extraction Rate (ER) Gain.13 This directly implies that optimizing the prompt itself, making it reactive to the input context, can be a key to revealing more extensive memorization.
Influence on Specific Domains (e.g., Code Generation): The nature of the prompt has also been shown to influence memorization in specialized domains like code generation. Research investigating how evolving prompts through techniques such as mutation, paraphrasing, and code-rewriting affects the LLM's tendency to reproduce memorized code solutions has led to the development of "memorization scores" that correlate with the level of prompt-induced recall.7 This provides direct support for the hypothesis that the prompt's characteristics are a significant determinant of observed memorization.
The concept of "discoverable extraction" 8 using prefix-suffix, as employed by Cooper et al. 1 , represents one specific method for assessing memorization. However, the user's hypothesis correctly intuits that other prompt types—such as adversarial prompts or the dynamic soft prompts described in other studies 13 —could reveal different, potentially higher, levels of memorization not captured by the experimental setup of Cooper et al. This suggests that if a study primarily uses a "standard" or less aggressive prompting technique, it might be underestimating the potential for extraction under more sophisticated or targeted prompting conditions, a crucial consideration for the user's query.
2.2.3. System-Level Modulators
Beyond the direct user input, system-level configurations and defenses play a crucial role in modulating whether and how memorized data is reproduced:
System Prompts: These are pre-defined instructions or contexts provided to the LLM by its developers to guide its overall behavior, tone, personality, and adherence to operational rules. While their direct impact on verbatim reproduction of specific training sequences is not always explicitly detailed in research snippets, their role in setting the model's general behavioral posture (e.g., "be helpful and harmless," "do not generate copyrighted text") can indirectly affect its readiness to reproduce training data, especially if such reproduction is deemed "unhelpful," "harmful," or policy-violating by its alignment training.
Guardrails: These are safety mechanisms or filters designed to monitor and control LLM inputs and outputs, preventing violations of predefined policy guidelines.11 Guardrails can be engineered to detect and block attempts at prompt injection, jailbreaking, and the leakage of sensitive data, which can include excerpts of training data if Data Loss Prevention (DLP) filters are implemented.11 They typically analyze both user prompts (input guardrails) and the LLM's generated responses (output guardrails).11 The effectiveness of guardrails can vary; they may exhibit false positives (incorrectly blocking benign content) or false negatives (failing to block harmful or policy-violating content).11 A critical interplay exists between the model's inherent alignment (its training to behave safely) and the external guardrails; alignment aims for naturally safe outputs, while guardrails provide an additional checkpoint for rule enforcement and edge-case handling.11 The presence, design, and strictness of guardrails, therefore, directly influence whether a given prompt can successfully elicit verbatim training data. A successful verbatim extraction via a prompt often implies either that the guardrails were insufficient for that specific case or that the prompt was sophisticated enough to bypass them.
Decoding Parameters (Temperature/Entropy): These parameters control the stochasticity of the LLM's output generation process.
Temperature: This parameter adjusts the shape of the probability distribution over the vocabulary from which the next token is sampled. Lower temperature values (e.g., < 1.0) make the output more deterministic, concentrating probability mass on the most likely tokens. This can lead to more repetitive but also more predictable outputs, potentially increasing the likelihood of verbatim reproduction if the memorized sequence represents a high-probability continuation of the prompt.15 As temperature approaches 0, the process resembles greedy search.
Higher temperature values (e.g., > 1.0) flatten the probability distribution, increasing randomness and making the model more "creative" or "surprising" by allowing it to sample less probable tokens more often.15 This makes the verbatim reproduction of long, specific sequences less likely purely by chance but could potentially surface less probable memorized items, albeit often at the cost of coherence.
Cooper et al. (2025) utilize a temperature T=1 with top-k sampling (k=40) for their probabilistic extraction experiments.1 This specific choice influences the calculated pz values. The "long tail" problem in decoding, where the aggregated probability of many low-probability tokens can lead to incoherent text, is a known issue, particularly with pure sampling (T=1) if not managed by strategies like top-k or top-p sampling.16 Thus, entropy settings are a direct modulator of observed memorization.
2.3. Conditions Favoring Verbatim Reproduction
Based on the factors discussed, verbatim reproduction of training data by LLMs is more likely to occur under the following conditions:
High frequency of the specific data sequence in the training corpus (data duplication).
Larger model sizes with greater capacity for memorization.
The use of specific, targeted prompts, especially those designed adversarially or dynamically optimized for extraction.
Lower temperature settings during decoding, leading to more deterministic and less random outputs.
The absence of effective guardrails, or the successful bypass of existing guardrails by sophisticated prompts.
When the memorized sequence represents a statistically highly probable continuation of the given prompt, according to the model's learned patterns.
The following table summarizes these key influencing factors:
Table 1: Factors Influencing LLM Verbatim Memorization
3. Critical Analysis of Cooper et al. (2025) 1
The paper by Cooper et al. (2025), "Extracting memorized pieces of (copyrighted) books from open-weight language models" 1 , serves as a central point of this analysis. It offers a detailed investigation into the extent of verbatim memorization of copyrighted books within several open-weight LLMs.
3.1. Overview of Research Aims, Methodology, and Key Findings
As established from a detailed review 1 , the primary aim of Cooper et al. is to investigate the extent to which 13 open-weight LLMs have memorized copyrighted material from the Books3 dataset. The authors endeavor to provide a more nuanced understanding of this phenomenon, moving beyond what they perceive as overly simplistic claims often made in the context of copyright lawsuits.1
The methodology employed is rooted in the concept of probabilistic extraction, specifically adapting the (n,p)-discoverable extraction technique from Hayes et al..8 The core of this approach involves calculating pz, defined as the probability that an LLM will generate a specific verbatim target suffix given a particular prefix.1 This pz value is then used to determine the number of prompts, 'n', that would be required to extract the target suffix with at least a probability 'p'.1 For their experiments, Cooper et al. primarily utilized top-k decoding with a temperature T=1 and k=40, and focused on 100-token examples, typically split into a 50-token prefix and a 50-token suffix.1 To identify regions of high memorization ("hot-spots") within books, they employed a "panning for gold" strategy, which involves analyzing overlapping 100-token chunks generated by sliding a 10-character window across the entire text of each book.1
Continue reading here (due to post length constraints): https://p4sc4l.substack.com/p/the-cooper-et-al-2025-paper-provides
