- Pascal's Chatbot Q&As
- Posts
- Significant technical, practical, and interpretative challenges remain in implementing effective, scalable, and globally recognized AI content control mechanisms.
Significant technical, practical, and interpretative challenges remain in implementing effective, scalable, and globally recognized AI content control mechanisms.
Addressing these challenges will require multi-stakeholder collaboration to balance the drive for AI innovation with the imperative to protect creator rights and foster a sustainable digital ecosystem.
Pascal Hetzscholdt
May 13, 2025
by Gemini Advanced, Deep Research with 2.5 Pro. Warning, LLMs may hallucinate!
1. Executive Summary
The proliferation of Generative Artificial Intelligence (GenAI) has precipitated an escalating challenge in governing the ingestion of vast quantities of web data required for training sophisticated AI models. This situation has created a fundamental tension between the data appetites of AI developers and the rights and economic interests of content creators. The core issue revolves around establishing effective mechanisms that allow content creators to express and enforce their preferences regarding the use of their work for AI training, a problem that traditional tools like the Robots Exclusion Protocol (robots.txt) are ill-equipped to handle effectively.1
Discussions within forums such as the Internet Engineering Task Force (IETF) AI-CONTROL workshop have underscored the inadequacy of robots.txt in its current form for the nuanced demands of AI content control.3 These discussions have explored a spectrum of potential solutions, including extensions to robots.txt, the development of new dedicated protocols like AITXT, the use of embedded metadata to signal rights and permissions at the content level, and even cryptographic verification methods for crawlers.4 A consensus is emerging that no single solution will suffice, pointing towards a future requiring multi-layered approaches.
Concurrently, the global legal and regulatory landscape is rapidly evolving. The European Union's AI Act, with its specific obligations for General-Purpose AI (GPAI) models concerning transparency and copyright compliance, is a landmark development.8 The associated GenAI Code of Practice, under development and anticipated to be finalized in mid-2025, aims to provide detailed guidance on implementing these obligations, including the respect for machine-readable opt-out signals from rights holders.10 This regulatory push is complemented by a notable increase in copyright infringement litigation targeting AI companies 12 and a significant rise in websites actively blocking AI scrapers, with Stanford's 2025 AI Index Report indicating that 20-33% of common crawl content was restricted by 2024-2025, a sharp increase from previous years.14
The path forward necessitates a synergistic combination of robust technical standards, clear legal frameworks, and adaptable industry best practices. However, significant technical, practical, and interpretative challenges remain in implementing effective, scalable, and globally recognized AI content control mechanisms. Addressing these challenges will require sustained multi-stakeholder collaboration to balance the drive for AI innovation with the imperative to protect creator rights and foster a sustainable digital ecosystem.
2. The Evolving Challenge of AI Content Ingestion and the Call for Control
The advent of powerful AI models, particularly large language models (LLMs) and generative AI, has fundamentally altered the dynamics of web data utilization. Historically, web crawling was predominantly associated with search engines, which often operated in a somewhat symbiotic relationship with content creators; websites provided data, and search engines provided visibility and traffic.4 However, the use of web data for training AI models presents a different paradigm. This new form of data consumption is often perceived by creators as extractive, where vast amounts of content are ingested to build commercial AI products that may compete with or devalue the original works, frequently without direct compensation, clear attribution, or demonstrable return value to the source.4
This shift has given rise to a host of concerns among content creators, publishers, and rights holders, fueling an urgent call for more effective control mechanisms. These concerns are multifaceted:
Copyright Infringement: The unauthorized reproduction and derivative use of copyrighted texts, images, audio, and video for training AI models is a primary concern.18 Numerous lawsuits have been filed globally, alleging that such practices infringe on the exclusive rights of copyright holders.12 The core legal debate often centers on whether AI training constitutes "fair use" (in jurisdictions like the US) or falls under specific exceptions like Text and Data Mining (TDM) provisions in other regions, and under what conditions.12
Economic Impact: Creators fear that AI models trained on their work will lead to the devaluation of their original content, direct competition from AI-generated alternatives, and a loss of licensing opportunities.4 The creative industries, in particular, have voiced anxieties about the potential for AI to undermine their economic viability if their content is used without permission or remuneration.22
Privacy Violations: Web content often contains personal data, and its ingestion into AI training datasets raises significant privacy issues, especially when done without the explicit consent of individuals whose data is processed.14 Regulatory frameworks like the EU's General Data Protection Regulation (GDPR) and emerging AI-specific data governance rules are increasingly scrutinizing these practices.28
Ethical Use and Consent: Beyond legal compliance, there are broader ethical questions about the lack of explicit consent for data use in AI training, the potential for AI models to perpetuate biases present in the training data, and the generation of misinformation or harmful content.14
The collective weight of these concerns has led to what some observers term a "consent crisis".31 Evidence of this growing resistance is seen in the "shrinking AI data commons." Research presented at the IETF AI-CONTROL workshop and findings from Stanford's 2025 AI Index Report highlight a dramatic increase in websites implementing restrictions against AI crawlers. Over a single year (2023-2024), the proportion of tokens in the C4 dataset (a common web crawl dataset) fully restricted from AI use by robots.txt or terms of service rose significantly, with estimates suggesting that 20-33% of common crawl content faced such restrictions by early 2025, up from 5-7% previously.14 This trend underscores a clear attempt by content providers to reassert control over their digital assets.
This push for control is also a tacit acknowledgment of the inadequacy of existing mechanisms, primarily the Robots Exclusion Protocol (robots.txt), as specified in RFC 9309. Originally designed in the 1990s to manage the behavior of relatively simple web crawlers and prevent server overload, robots.txt is ill-suited for the complex requirements of AI data governance.1 Its limitations are numerous and widely recognized:
Lack of Granularity: Robots.txt typically operates at a site or directory level and cannot easily distinguish between different types of crawlers (e.g., search engine indexers versus AI training scrapers) or different intended uses of the data (e.g., allowing indexing for search but prohibiting use for AI model training).4
Voluntary Compliance: The protocol relies on the voluntary adherence of crawlers. While reputable search engines generally respect robots.txt directives, there is no technical enforcement mechanism to prevent less scrupulous actors or determined AI developers from ignoring these instructions.4
Inapplicability to Non-Crawled Data: Robots.txt only governs direct crawling of a website. It offers no control if content is accessed through other means, such as APIs (unless specified by API terms), or if it is part of third-party datasets aggregated from various sources.4 Once data is copied, robots.txt has no further influence.
Content vs. Location Rights: Rights, particularly copyright, adhere to the content itself, not merely its location on a website. Robots.txt is a location-based control and cannot effectively manage rights at the individual content item level.4
The fundamental nature of the implicit agreement between websites and automated agents is thus undergoing a significant renegotiation. The previously common stance, which was generally permissive to allow for search engine visibility and discovery, is shifting towards a more restrictive posture in the face of AI's intensive data demands. This shift is not merely a technical adjustment but reflects a deeper re-evaluation of data value, creator rights, and the ethical responsibilities associated with building and deploying powerful AI systems. The "consent crisis" is not solely a copyright issue; it encompasses a broader spectrum of economic, privacy, and ethical considerations, making the design of comprehensive and effective control solutions a complex, multi-dimensional challenge.18
3. Proposed Mechanisms for AI Content Control: An IETF Perspective
Recognizing the escalating challenges and the limitations of existing tools, the Internet Architecture Board (IAB) convened the AI-CONTROL workshop (aicontrolws) to explore practical opt-out mechanisms for AI crawlers.1 The workshop's primary focus was on the signaling mechanisms that content creators could use to communicate their preferences regarding the use of their data for AI training, rather than on the technical enforcement of these signals. While robots.txt served as an initial anchor for discussions, the workshop explicitly welcomed proposals for alternative solutions.1
The proposals and discussions emerging from this IETF initiative and related forums can be broadly categorized, revealing a trajectory from adapting existing tools to envisioning entirely new frameworks.
3.1. Robots.txt Extensions: Leveraging Familiar Infrastructure
A significant portion of the discussion centered on extending the robots.txt protocol, given its widespread adoption and familiarity among web administrators.33 The rationale is that leveraging this existing infrastructure could offer a pragmatic path for expressing AI-specific preferences. Proposed extensions included:
AI-Specific User-Agents: Introducing new user-agent tokens that clearly identify crawlers used for AI training (e.g., AI-crawler, LLM-trainer, or more specific ones like OpenAI's GPTBot 20 ) would allow website owners to differentiate them from traditional search engine crawlers and apply distinct rules.4 Google's google-extended directive, allowing opt-out from use in its Vertex AI generative APIs while still permitting search indexing, serves as an early commercial example of this approach.4
New AI-Specific Directives: Proposals for new directives such as AI-Allow / AI-Disallow or more targeted directives like NoAITraining or AIPurpose: [purpose] aim to provide explicit means for content owners to grant or deny permission for AI-related uses.32
Enhanced Granularity: Some proposals focused on adding URI-level control extensions to robots.txt or through HTML meta tags and HTTP headers, allowing for more fine-grained permissions for specific pages or resources rather than just site-wide or directory-level rules.38
However, relying solely on robots.txt extensions also means inheriting its fundamental limitations. These include its voluntary nature, the difficulty of ensuring compliance, its inability to control data use once copied, and its primarily location-based (rather than content-based) control.2 Furthermore, the proliferation of numerous AI-specific user agents or purpose directives could lead to overly complex robots.txt files that are difficult to manage and standardize.
3.2. Novel Signaling Protocols and Standards: Moving Beyond robots.txt
The acknowledged shortcomings of robots.txt spurred proposals for entirely new protocols and standards designed with the specific needs of AI content control in mind:
AITXT: Proposed by entities like Guardian News & Media and the startup Spawning, AITXT is envisioned as a dedicated file, complementary to robots.txt.5 It would allow for more granular AI-specific permissions, potentially including directives on whether content can be used for AI training, limitations on snippet length for AI outputs, requirements for attribution, or terms for licensing.5
TDM-AI (Text and Data Mining for AI): This proposal focuses on creating a robust link between content and its usage permissions by binding restrictions or allowances to content-derived identifiers, such as the International Standard Content Code (ISCC), and associating these with creator credentials (e.g., W3C Verifiable Credentials).39 The goal is to achieve a unit-based opt-out declaration that remains inseparably bonded to the content, regardless of its location.
Server-to-Client Privacy Opt-Out Preference Signal: This concept involves a direct communication channel from the server to the client (including AI crawlers) to signal privacy preferences regarding content access and use.40
Delegated Authorization Standard: Arguing that robots.txt is fundamentally insufficient for the complex authorization requirements of AI systems, some proponents advocate for a new, more sophisticated and granular standard for delegated access control specifically for AI resources.41
Multi-Level Approaches: Recognizing that no single mechanism may be universally effective, some suggest combining existing web standards with new methods to create a more comprehensive content protection strategy.42
A critical distinction in these new proposals is between location-based and unit-based (or content-level) signals. Robots.txt and AITXT are primarily location-based, defining rules for accessing content at a specific URL or path.5 While simpler for site administrators to implement for broad policies, this approach is less effective for individual creators who may not control the server or robots.txt file where their content is hosted (e.g., on social media platforms or third-party repositories).34 Unit-based signals, such as embedded metadata or the TDM-AI proposal, attach preferences directly to individual content items.6 This is seen as crucial by many creators because rights, particularly copyright, adhere to the work itself, not its temporary online location.4 The challenge for unit-based signals lies in standardization, widespread adoption by creation tools and platforms, and preventing the loss or alteration of these signals (e.g., metadata stripping 34 ).
3.3. Metadata and Cryptographic Approaches: Enhancing Trust and Specificity
Embedded Metadata: The International Press Telecommunications Council (IPTC) and the PLUS Coalition have proposed using embedded Extensible Metadata Platform (XMP) metadata within digital image and video files to communicate data mining rights information.6 This would allow creators to specify permissions, prohibitions, or constraints regarding data mining directly within the content file. However, the widespread issue of metadata stripping during content upload to platforms or through various workflows poses a significant challenge to this approach.34
Cryptographically Verified Bots (CVB): Cloudflare has proposed a system for cryptographic verification of bots, suggesting a change to the TLS specification called "Request mTLS".7 This would allow AI crawlers to present a verifiable certificate, enabling servers to authenticate them and make more informed decisions about granting access. Cloudflare argues that transparency through verifiable identity is a more robust foundation for trust than the often fragile and easily spoofed User-Agent strings used in robots.txt.7
3.4. The Opt-In Versus Opt-Out Default Debate
Underlying many technical discussions is a fundamental policy and legal question: should the default for AI training use be opt-in (permission is required explicitly) or opt-out (use is permitted unless explicitly restricted)?
Some stakeholders, particularly content creators and their advocates, argue for an opt-in default, asserting that permission for a new use like AI training should not be presumed and must be affirmatively granted.4 This perspective was echoed by some participants in IETF AIPREF discussions, suggesting a default of "no" with specific opt-ins for various uses.43
Conversely, legal frameworks like the EU's Copyright in the Digital Single Market (CDSM) Directive (Article 4) establish a TDM exception that effectively functions as an opt-out system: rights holders can reserve their rights to prevent TDM, but if they do not, TDM for research or other purposes (depending on the specifics of Article 3 vs. Article 4) may be permitted.19 AI developers often favor opt-out regimes or broad exceptions to maximize data access.35
The IETF AIPREF (AI Preferences) working group, tasked with developing vocabularies and mechanisms for expressing these preferences, has acknowledged the need to support signaling for both opt-in and opt-out modalities.33 This recognizes that the determination of the legal default is a policy matter outside the IETF's direct purview, but technical standards must be versatile enough to accommodate different legal and policy choices. The "no signal" state, representing the vast majority of existing web content, remains a complex area, currently deemed "out of scope" by some working group discussions, highlighting a significant gap in current approaches.33
The trajectory of these discussions indicates a clear movement from attempting to retrofit an old tool (robots.txt) to recognizing the necessity for fundamentally new, more expressive, and granular mechanisms tailored to the complexities of AI. While robots.txt may serve as a pragmatic interim measure due to its ubiquity, the long-term solutions are likely to involve a combination of these newer approaches. The EU AI Act's Code of Practice, for instance, acknowledges robots.txt but also explicitly anticipates the use of "other appropriate machine-readable protocols," signaling regulatory openness to more robust solutions.11
4. Stakeholder Perspectives and Diverging Interests
The debate surrounding AI content control is characterized by a diverse array of stakeholders, each with distinct interests, concerns, and proposed solutions. Understanding these perspectives is crucial for developing balanced and effective governance mechanisms. The IETF AI-CONTROL workshop served as a venue for many of these voices to be heard.1
4.1. Content Creators and Publishers
This group, encompassing individual authors, artists, journalists, news organizations (e.g., Guardian News & Media 5 , BBC 32 ), academic publishers (e.g., Elsevier 47 ), and industry bodies like the IPTC 6 , is at the forefront of demanding stronger control over how their content is used for AI training. Their primary motivations include:
Upholding Copyright and Intellectual Property Rights: They assert that the unauthorized ingestion of their works for training commercial AI models constitutes copyright infringement and undermines their ability to control and benefit from their creations.4
Ensuring Fair Compensation and Licensing: Many advocate for mechanisms that facilitate licensing agreements and ensure they are fairly compensated when their content contributes value to AI models.4 The BBC, for example, argues that current scraping practices without permission are not in the public interest and seeks a more structured approach with tech companies.32
Maintaining Economic Viability: There are significant concerns that AI-generated content, trained on their works, could devalue original human creativity, saturate markets, and diminish their livelihoods.17
Demanding Granular Control: Publishers and creators often seek content-specific control mechanisms rather than just site-wide opt-outs, as the rights and desired uses can vary significantly from one piece of content to another.6 Proposals like AITXT from Guardian News & Media 5 and embedded metadata from IPTC/PLUS 6 reflect this need.
Attribution and Integrity: Concerns also exist around the lack of attribution for source material used in AI training and the potential for AI to misrepresent or distort original works.
While Elsevier acknowledges the potential of GenAI to enhance search and discovery in scientific literature, their position implies a need for careful and controlled deployment.47
4.2. AI Developers
AI developers, ranging from large corporations like OpenAI 35 and IBM 49 to smaller startups, emphasize the necessity of accessing large, diverse datasets to build capable, innovative, and unbiased AI models.35 Their key considerations include:
Data Requirements for Innovation: They argue that broad access to web data is crucial for advancing AI technology and ensuring models are knowledgeable across many domains, languages, and cultures.35
Feasibility and Scalability of Opt-Outs: Developers express concerns about the technical complexity, operational cost, and scalability of implementing systems to identify and respect a multitude of potentially inconsistent opt-out signals from across the web.24
Impact on Model Quality and Innovation: Widespread opt-outs or overly restrictive data access regimes could, from their perspective, lead to less capable, more biased AI models, potentially hindering innovation and the societal benefits of AI.14 OpenAI, for example, has raised concerns that if most copyrighted data becomes unavailable, only the wealthiest tech companies could access sufficient data, harming broader AI development.44
Self-Governance and Responsible Practices: Some developers, like IBM, highlight their commitment to internal self-governance policies for the acquisition and use of public data.49 OpenAI has stated its aim to respect creator choices while also underscoring the benefits of diverse training data.35
Technical Challenges: Developers face significant technical hurdles in areas like efficiently filtering datasets post-collection to remove opted-out content and the complex, often impractical, task of "machine unlearning" or selectively forgetting data from already trained models.50
4.3. Platform Providers
Internet infrastructure and platform providers, such as Cloudflare 7 and GitHub 37 , play a crucial role as intermediaries and potential enablers of control mechanisms.
Cloudflare emphasizes transparency as a prerequisite for control, proposing cryptographic verification of bots (CVB) using technologies like Request mTLS as a more trustworthy alternative or supplement to robots.txt for bot identification.7
GitHub focuses on the needs of software developers using its platform, advocating for ways for them to easily express preferences regarding the use of their code and other content for AI training, suggesting adaptations to robots.txt could serve this purpose.37 These platforms are uniquely positioned to implement or facilitate control signals at a large scale, but their solutions often reflect their specific business models and user bases.
4.4. Civil Society and Rights Advocates
Organizations like the Center for Democracy & Technology (CDT) 18 , Creative Commons (CC) 54 , and individual advocates (e.g., Thomson and Eggert 55 ) champion user rights, ethical AI development, and public interest considerations.
CDT calls for balanced, standards-based solutions that protect content creators, allow AI companies to innovate, and ensure researchers can access data for public benefit.18
Creative Commons advocates for extending the principles of user choice and control, central to its licensing framework, to the realm of machine use of content, emphasizing the need for clear preference signals.54
Thomson and Eggert argue for a simple, textual opt-out signal to empower individuals to control how their data is used.55 These groups often focus on transparency, accountability, privacy, preventing algorithmic bias, and ensuring that AI development serves broad societal interests rather than narrow commercial ones.
4.5. Researchers
The academic and scientific research community has a distinct stake in data access.
Researchers like Sinha 36 and Longpre et al. 31 express concerns that overly broad or poorly designed opt-out mechanisms could significantly hinder access to data necessary for scientific inquiry, public interest research, and understanding AI systems themselves.
The "shrinking AI data commons" due to increasing restrictions is seen as a threat to the diversity, freshness, and scale of data available for non-commercial research, potentially skewing AI development and limiting independent scrutiny.15
They often advocate for specific carve-outs or considerations for research access within any new control frameworks to ensure that legitimate research is not unduly impeded.18
The diverse and often conflicting interests of these stakeholder groups illustrate the complexity of the AI data governance challenge. What one group views as an essential control mechanism to protect rights and livelihoods, another may perceive as an undue burden or an impediment to innovation and research. This divergence makes finding a universally accepted "one-size-fits-all" solution exceptionally difficult. It necessitates approaches that are flexible, perhaps tiered, and capable of accommodating different needs and use cases. The IETF AI-CONTROL workshop itself was an early attempt to bridge these divides by bringing these varied perspectives into a shared forum.1
Despite the conflicts, there appears to be a growing, albeit sometimes reluctant, acknowledgment, even among some AI developers, that some form of respecting creator preferences is becoming unavoidable. This is driven by mounting legal challenges 12 , public and creator backlash 33 , and increasing regulatory pressure, particularly from the EU.8 Consequently, the debate is gradually shifting from whetherto implement controls to how to design and implement them in a way that is effective, technically feasible, and reasonably balances the competing interests. The active participation of major AI players in drafting the EU's Code of Practice 10 and in initiatives like C2PA for content provenance 44 signals this evolving engagement.
Furthermore, the very definition of "AI" and its various applications is becoming a critical point of differentiation for control mechanisms. The initial focus has largely been on data ingestion for training LLMs.1 However, AI systems perform a range of web-crawling functions. OpenAI, for instance, distinguishes user agents for training data collection (GPTBot), for augmenting AI assistants (ChatGPT-User), and for AI-backed search (SearchBot).20 Content creators are likely to have different preferences for these distinct uses—perhaps allowing crawling for search indexing while disallowing it for model training.33 This necessitates signaling mechanisms capable of expressing such granular distinctions, a capability that current robots.txt struggles to provide but which newer proposals and vocabulary development efforts, like those within the IETF AIPREF working group 43 , aim to address by considering the impact on participants rather than just the specific technology.
5. The Global Regulatory and Legal Landscape for AI Data Governance
The technical discussions around AI content control are unfolding against a backdrop of rapidly evolving legal and regulatory frameworks worldwide. Governments and courts are increasingly grappling with the implications of AI data ingestion, particularly concerning copyright, privacy, and transparency. The European Union is notably at the forefront of these efforts, but significant developments are also occurring in other major jurisdictions.
5.1. The European Union: The AI Act and the GenAI Code of Practice
The EU AI Act, which formally entered into force in August 2024, represents the world's most comprehensive piece of legislation specifically targeting AI systems.8 It adopts a risk-based approach, categorizing AI systems and imposing obligations accordingly. Of particular relevance are the provisions for General-Purpose AI (GPAI) models, including most large foundation models, whose rules are set to become effective in August 2025.8
Article 53 of the AI Act imposes key obligations on GPAI model providers:
Transparency in Training Data: Providers must draw up and make publicly available a "sufficiently detailed summary" of the content used for training their models.10 The European AI Office is developing a template for this summary, which is intended to allow creators and rights holders to understand what data has been used.50
Copyright Compliance Policy: Providers must establish and implement policies to ensure compliance with EU copyright law. Crucially, this includes identifying and respecting any reservation of rights expressed by rights holders under Article 4(3) of the Copyright in the Digital Single Market (CDSM) Directive (Directive (EU) 2019/790).11 Article 4(3) CDSM allows rights holders to opt out of having their publicly accessible works used for text and data mining.
To elaborate on these obligations, the European AI Office is facilitating the drafting of a General-Purpose AI Code of Practice (CoP). This CoP is being developed through an iterative, multi-stakeholder process involving AI providers, rights holders, civil society, and academia, with a final version anticipated in May 2025 and publication by August 2025.10 The third draft, released in March 2025, provided more streamlined commitments.11
Key copyright-related measures outlined in the draft CoP include:
Providers must draw up, keep up-to-date, and implement an internal copyright policy, and are encouraged to publish a summary.11
When crawling the web for training data, providers must identify and comply with rights reservations (opt-outs). Specifically:
They must employ web crawlers that can read and follow instructions expressed in accordance with robots.txt.11
They must make "best efforts" to identify and comply with "other appropriate machine-readable protocols" (e.g., asset-based or location-based metadata) that have either resulted from a cross-industry standard-setting process or are "state-of-the-art and widely adopted by rightsholders".11
Providers must make reasonable efforts to avoid circumventing technical protection measures (e.g., paywalls) and to exclude "piracy domains" from their crawling activities.46
When using third-party datasets, providers must make reasonable efforts to obtain information about the dataset's copyright compliance, including whether robots.txt instructions were followed during its collection.46
Providers must take reasonable efforts to mitigate the risk of their models memorizing training content to an extent that leads to repeatedly generating copyright-infringing outputs.46
The phrase "other appropriate machine-readable protocols" is pivotal and currently subject to interpretation and ongoing development. The AI Office's Q&A 59 and the CoP drafts 11 do not yet provide an exhaustive list or endorse specific protocols like AITXT or particular metadata standards by name. Instead, the emphasis is on protocols emerging from cross-industry standardization or those achieving wide adoption and representing the state of the art.45 This approach aims to foster the development and adoption of effective technical standards. Paul Keller's paper, referenced in EU-related discussions, distinguishes between location-based protocols (like robots.txt and potentially AITXT) and unit-based protocols (like metadata tags attached to specific works), highlighting the different levels of control they offer.45 The European Copyright Society has urged for clarity on the modalities, timing, and location of opt-out expressions and for a regular review of the technologies used to express such reservations.51
The development and implementation of the EU AI Act and its CoP are not without political debate and challenges. These include striking a balance between fostering innovation and protecting fundamental rights 8 , concerns about the EU's competitiveness against US dominance in GenAI 62 , the precise scope of exemptions (e.g., for national security 63 ), and clear definitions of terms like "provider" and "placing on the market" to ensure accountability along the complex AI value chain.57 There are also concerns from some AI developers that overly effective or widespread opt-outs could severely limit data availability, thereby hindering model development or disproportionately benefiting only the largest companies with existing vast datasets.24 The transaction costs associated with negotiating numerous individual licenses and the potential for training data to become skewed towards mainstream works if niche content is widely opted-out are further practical concerns.24
The EU AI Act is poised to have a significant global impact, potentially creating a "Brussels effect" where its standards become de facto global norms for AI governance, much like GDPR did for data privacy.9 Multinational AI companies will likely need to align their global operations with these stringent EU requirements to access the substantial EU market. The inclusive nature of the CoP drafting process, involving international stakeholders 10 , further suggests that its outcomes will influence the development and adoption of technical standards for AI content control worldwide.
5.2. Copyright Law and AI: A Litigious Frontier
Parallel to regulatory developments, copyright law is being actively tested in courts worldwide. A wave of high-profile lawsuits has been filed by authors, artists, publishers, and stock photo agencies against AI companies, alleging that the unauthorized use of their copyrighted works to train AI models constitutes infringement.12 Key cases include:
Andersen et al. v. Stability AI et al. (artists suing image generators).
Getty Images v. Stability AI (stock photo agency suing image generator).
Various authors' groups suing OpenAI and Meta.
Thomson Reuters Enterprise Centre GMBH v. Ross Intelligence Inc.: In this case concerning a non-generative AI legal research tool, a US federal district court, in rulings in February 2024 and February 2025, found that Ross's use of Thomson Reuters' Westlaw headnotes (short summaries of legal points) to train its AI was direct copyright infringement and not fair use.12 The court emphasized the commercial nature of Ross's use, its lack of transformativeness (as it directly competed with Westlaw's offerings using its content), and the negative impact on the market for Westlaw's product. Judge Bibas, however, explicitly noted that his ruling was specific to the non-generative AI at issue and that the analysis might differ for generative AI models, which defendants often argue are more transformative.13
The "transformative use" doctrine under US fair use law is a central argument for many AI defendants. They contend that using copyrighted works as training data to create new, functionally different AI models that generate novel outputs is a transformative purpose, rather than mere replication.12 The outcomes of these ongoing lawsuits will be pivotal in shaping the legal boundaries for AI training data.
This legal uncertainty, coupled with creator concerns, is a significant driver behind the observed increase in websites blocking AI scrapers. The Stanford AI Index Report 2025 highlighted that between 20-33% of common crawl content was restricted by early 2025, a substantial jump from 5-7% the previous year, indicating a clear defensive posture by many content hosts.14
5.3. Developments in Other Key Jurisdictions (2024-2025)
While the EU leads with a comprehensive horizontal regulation, other countries are developing their own approaches to AI governance and the TDM/copyright interface:
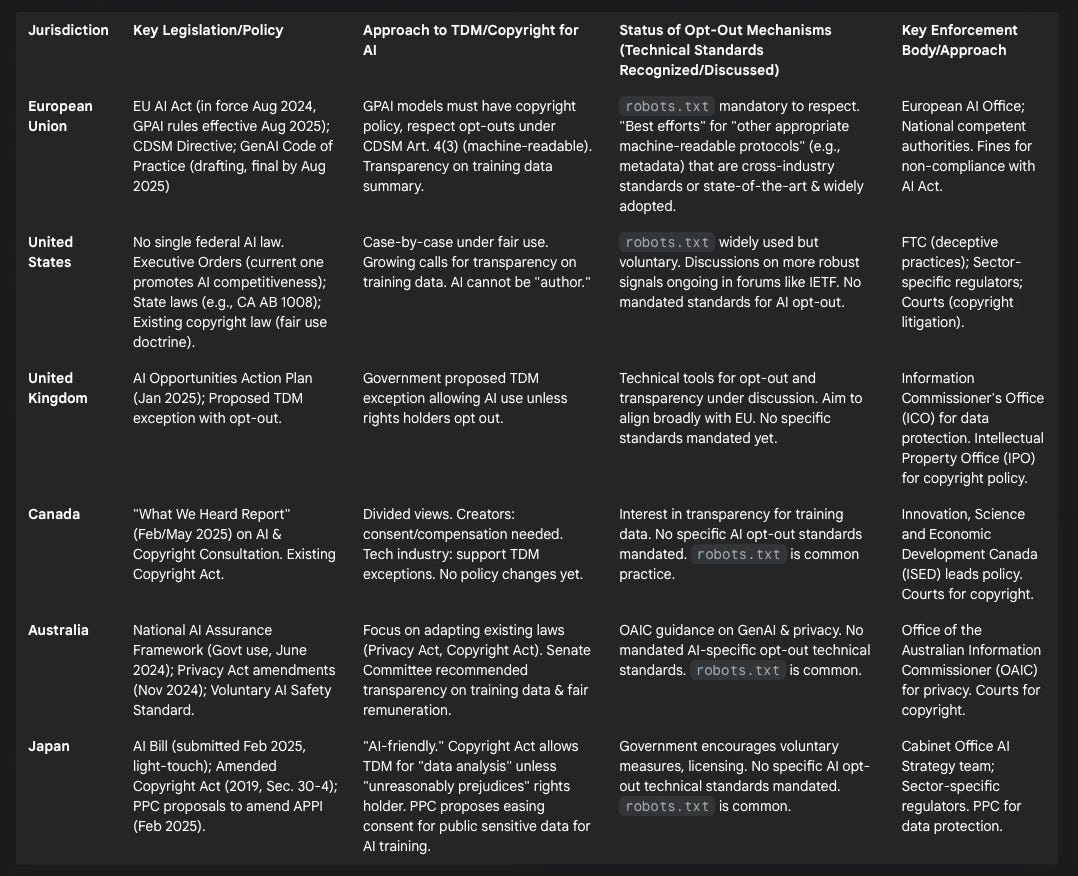
United States: The US currently lacks a comprehensive federal AI law, relying instead on a patchwork of existing laws, sector-specific regulations, and executive actions.26 The Biden Administration's Executive Order on AI Safety was rolled back by the Trump Administration, which issued a new EO focused on AI competitiveness.26 The Office of Management and Budget (OMB) has issued memoranda guiding federal agencies on AI use, risk management, and procurement, emphasizing responsible deployment and American-developed technologies.64 The Federal Trade Commission (FTC) has been active in enforcement related to AI claims and data practices.64 Several states, notably California, are advancing their own AI-related legislation. California's AB 1008 (effective Jan 1, 2025) amends the California Consumer Privacy Act (CCPA) to include AI-generated personal information, and the California Privacy Protection Agency (CPPA) is developing rules for consumer opt-out of Automated Decision-Making Technology (ADMT).26 Other state-level bills address issues like deepfakes, data broker activities, and requirements for developers to document copyrighted materials used in AI training.65 In a significant copyright ruling, the DC Circuit Court held that an AI system cannot be recognized as an "author" under US copyright law.64
United Kingdom: The UK government has signaled a commitment to becoming a global leader in AI through its AI Opportunities Action Plan (announced January 2025).22 It has proposed a text and data mining (TDM) exception to copyright law that would allow AI development while also providing a mechanism for rights holders to opt out of having their data used.22 This approach aims to bring UK regulation broadly in line with the EU's TDM exception. However, the proposal has faced criticism from both sides: some creative industry representatives argue that any broad commercial TDM exception is problematic and undermines their rights 22 , while some AI proponents warn that extensive opt-outs could lead to poorly trained, biased models and stifle innovation.23 Discussions are ongoing regarding the effectiveness of technical tools for opt-outs, transparency from AI developers, the establishment of clear standards for creativity and licensing in AI applications, and distinguishing between human-generated and AI-generated works for attribution and remuneration.22
Canada: Following a consultation on "Copyright in the Age of Generative Artificial Intelligence" (October 2023 - January 2024), the Canadian government released a "What We Heard Report" in early 2025 (February/May, sources vary).21 The report indicated divided stakeholder views on TDM: creators and cultural industries largely opposed the use of their content for AI training without consent and compensation, while technology industry stakeholders generally supported clarifications to copyright law or new exceptions to facilitate TDM.21 There was notable consensus on keeping human authorship central to copyright protection and significant interest in greater transparency regarding the data used for AI training. However, the Canadian government has not yet announced concrete policy actions or legislative changes based on this consultation.48
Australia: Australia has thus far adopted a less prescriptive approach, focusing on voluntary standards, guidance, and adapting existing laws rather than enacting comprehensive AI-specific legislation.28 The National Framework for the Assurance of AI in Government (June 2024) provides a consistent approach for public sector AI use.68 Recent amendments to the Privacy Act 1988 (passed November 2024) introduced reforms such as increased transparency for automated decision-making involving personal information and a new statutory tort for serious invasions of privacy.30 The Office of the Australian Information Commissioner (OAIC) has issued guidance on privacy and generative AI, emphasizing principles like fair and lawful collection of personal information (even if publicly available) and the need for consent for using sensitive information in AI model training.28 A Senate Select Committee on Adopting Artificial Intelligence, in its final report (November 2024), recommended transparency from AI developers regarding copyrighted works in training datasets and ensuring fair remuneration for creators when AI generates outputs based on their material.30
Japan: Japan is actively pursuing an "AI-friendly" regulatory environment, aiming for a lighter touch than the EU.29 The government's approach emphasizes reliance on existing sector-specific laws and voluntary industry measures, in line with technological neutrality.69 An AI Bill submitted to Parliament in February 2025, if enacted, would be Japan's first comprehensive AI law but primarily imposes an obligation on private sector entities to "cooperate" with government-led AI initiatives, while tasking the government with developing AI guidelines and conducting research.29 Japan amended its Copyright Act in 2019 (Section 30-4) to permit the exploitation of copyrighted works for "data analysis" (including TDM for AI training) as long as it does not "unreasonably prejudice the interests of the copyright owner".70 Furthermore, in February 2025, Japan's Personal Data Protection Commission (PPC) proposed amendments to the data protection law (APPI) to facilitate the use of personal data for AI development, suggesting that publicly available sensitive personal data could be collected without consent for AI model training if the results cannot be traced back to specific individuals.29 The government also encourages AI businesses and rights holders to find contractual terms and licensing deals to resolve differences.70
This global divergence in regulatory philosophies—from the EU's comprehensive, rights-protective stance to Japan's innovation-focused, lighter-touch regime, with others like the UK, US, Canada, and Australia navigating various intermediate paths—creates a complex and fragmented compliance landscape for global AI companies.27 The legal interpretation of what constitutes an "appropriate machine-readable" opt-out signal is also still evolving and is critical for the practical enforcement of copyright reservations. While the EU's CDSM Directive allows opt-outs via such means 19 , and the draft EU CoP points towards robots.txt and other emerging standards 11 , the precise definition and legal weight of different signals are being actively debated and clarified. A German court, for example, has interpreted "machine-readable" broadly 11 , but broader consensus and standardization are still needed. The AI Office's future guidance and refinements to the CoP will be crucial in this regard.28
The following table provides a comparative overview of these diverse approaches:
Table 1: Comparative Overview of AI Data Governance and Opt-Out Policies (2024-2025)
6. Technical and Practical Challenges in Implementing AI Opt-Outs
While legal and policy frameworks are beginning to mandate that AI developers respect content creators' preferences, the technical and practical implementation of effective, scalable, and verifiable opt-out systems presents substantial challenges. These hurdles span the entire lifecycle of data, from initial collection to model training and potential post-hoc modifications.
Continue reading here (due to post length constraints): https://p4sc4l.substack.com/p/significant-technical-practical-and
