- Pascal's Chatbot Q&As
- Posts
- Self-hosting. Commercially available LLMs are increasingly hampered by cost-driven efficiency measures, such as aggressive quantization and output filtering, which often degrade reasoning performance.
Self-hosting. Commercially available LLMs are increasingly hampered by cost-driven efficiency measures, such as aggressive quantization and output filtering, which often degrade reasoning performance.
Influence of political sensitivities has introduced layers of ideological censorship and “over-refusal,” where models decline benign requests to avoid regulatory or reputational risk.
Pascal Hetzscholdt
April 06, 2026
The Case for Local Large Language Model Deployment: Performance, Cost, and Sovereignty in the 2026 Ecosystem
by Gemini 3.0, Deep Research. Warning, LLMs may hallucinate!
The trajectory of large language model (LLM) utilization has arrived at a critical juncture in early 2026. While the initial years of the generative artificial intelligence revolution were defined by the rapid adoption of centralized, cloud-based services, the current landscape is characterized by a strategic retreat from these proprietary platforms toward localized, sovereign deployments. This movement is not merely a preference for privacy but a pragmatic response to the structural limitations now plaguing commercial models. Commercially available LLMs are increasingly hampered by cost-driven efficiency measures, such as aggressive quantization and output filtering, which often degrade reasoning performance. Furthermore, the pervasive influence of political sensitivities has introduced layers of ideological censorship and “over-refusal,” where models decline benign requests to avoid regulatory or reputational risk. Consequently, for professional, research, and creative applications, the optimal method of utilizing LLMs has shifted toward self-hosting on capable local hardware. This report examines the technical, economic, and security dimensions of this shift, identifying the most effective local configurations and projecting the future of private AI.
Structural Decay in Commercial AI Services
The dominance of providers like OpenAI, Google, and Anthropic was built on the premise that frontier-level intelligence required data-center-scale compute. However, as these companies have sought to monetize their massive user bases, they have encountered the “efficiency paradox”.1 To maintain profitability while serving millions of concurrent users, providers have resorted to system-level optimizations that prioritize throughput over depth. This includes the use of aggressive quantization at the inference layer and the implementation of “lazy” response triggers that minimize the number of tokens processed for each query.2 These optimizations are often opaque to the end-user, leading to a perceived decline in model capability for complex instruction following or nuanced reasoning.2
Beyond fiscal constraints, the integration of LLMs into the global political discourse has made them targets for regulation and ideological alignment. Commercial models are no longer “raw” predictors of text; they are filtered through “Constitutional AI” frameworks and safety guardrails designed to reflect specific regional and corporate values.3 This has led to the emergence of both “hard censorship”—where a model flatly refuses to answer—and “soft censorship,” where the model provides a sanitized or propaganda-aligned response.3
Geopolitical and Ideological Refusal Patterns
The divergence in model behavior is increasingly linked to the geopolitical origin of the provider. Research into internet-wide LLM deployments indicates that models from different regions exhibit tailored strategies for their domestic audiences.6 For example, Russian and Chinese models demonstrate significantly higher refusal rates when queried about specific political figures or sensitive historical events relevant to their respective states.5 Conversely, Western models like Gemini and Claude have been observed to exhibit stronger “soft censorship” in the form of selective omissions or the imposition of specific cultural values during the reasoning process.3

The lack of transparency in these moderation strategies poses a significant risk for researchers in the humanities, history, and law.7 When AI providers implement arbitrary filtering mechanisms without academic oversight, they create “artificial gaps” in the information ecosystem.7 For instance, Anthropic’s policy documentation mentions domain-specific expert red-teaming but lacks significant contributions from the humanities, leaving models vulnerable to “accidental censorship” of historical or philosophical inquiries.7 This opacity undermines the objectivity required for professional analysis, driving the need for local models where the weights and alignment layers are either transparent or removable.
The Local Alternative: Parity and Customization
The primary driver for the feasibility of local LLMs in 2026 is the near-closure of the performance gap between open-weight and proprietary models. While proprietary “Elite” tier models like GPT-5.1 still lead on mission-critical benchmarks, open-weight models such as Llama 4, DeepSeek V3.2, and Qwen 3 have achieved scores within 7 to 9 points of the proprietary leaders in PhD-level reasoning and advanced mathematics.8 In the “High” tier—the sweet spot for professional content generation and coding—open-source models now match proprietary offerings in both number and quality.8
Benchmark Quality Comparison (2025-2026)
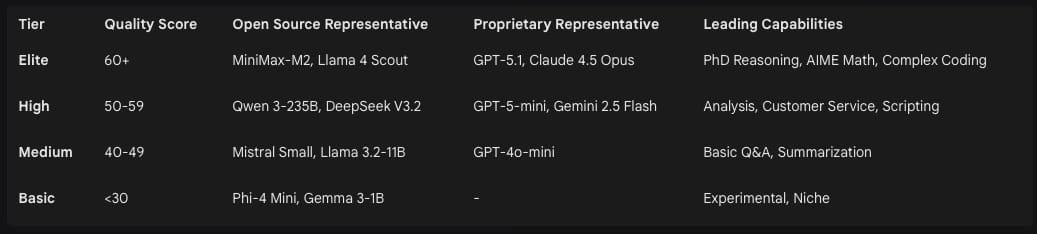
The most significant advantage of the local ecosystem is the ability to use “abliterated” models. These are community-developed versions of base models where the safety and alignment layers have been eroded through targeted fine-tuning.11 Models such as Dolphin Llama 3 and Nous Hermes 3 are designed specifically to remove the “alignment tax” that causes over-refusal in standard variants.11 These models excel in instruction following and provide unrestricted responses, making them indispensable for creative writing, simulation, and research where the model must not impose its own moral or safety constraints on the user.11
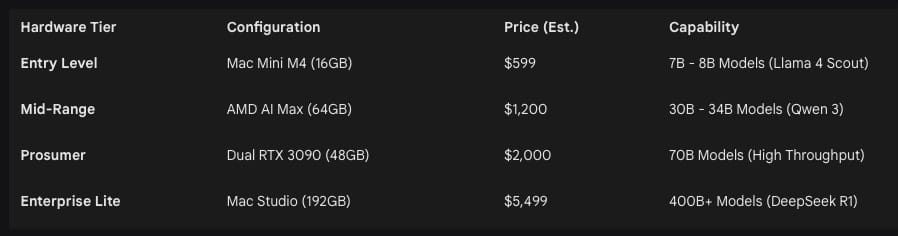
Hardware Architectures for Home Deployment

However, the 32GB limit on a single card remains a bottleneck for models exceeding 70B parameters. On PC platforms, adding a second card involves significant power (575W TDP per card) and thermal management challenges.13
Apple Silicon: The Unified Memory Paradigm
Apple’s Mac Studio and MacBook Pro offer the most realistic and simple path for running “massive” models. Because Apple uses a unified memory architecture (UMA), the entire system RAM is accessible to the GPU.14 A Mac Studio with M3 or M4 Ultra and 512GB of RAM can run models with 400B to 671B parameters, such as DeepSeek-R1, entirely in-memory—a feat that would require over $100,000 in enterprise GPU clusters.16
The M4 Ultra features a memory bandwidth of 819 GB/s, which is slower than a single RTX 5090 but significantly faster than any CPU-based RAM configuration.13 More importantly, the lack of a PCIe bottleneck means that token generation speed remains consistent even as model size increases.14 Real-world testing shows a Mac Studio M3 Ultra generating 8 tokens per second on a 70B model with low context, but maintaining that speed even as context windows grow, which is critical for long-form RAG (Retrieval-Augmented Generation).16
Budget-Friendly Options: NPU and Refurbished Hardware
For users seeking the cheapest “realistic” entry into local AI, two paths have emerged as superior to building a new gaming PC from scratch:
Refurbished Apple Silicon: A refurbished Mac Mini or Mac Studio with an M2 Pro or M3 Pro chip and at least 32GB of RAM provides a silent, power-efficient AI workstation.21 These machines eliminate the recurring $240/year subscription costs and can run 7B-13B models with zero configuration work.19
AMD Ryzen AI Max Mini PCs: The Strix Halo platform (Ryzen AI Max+ 395) features unified memory similar to Apple’s, offering up to 128GB of LPDDR5x in a mini-PC form factor for under $2,000.19 This platform offers significantly better price-to-VRAM value than Apple, allowing users to run full 70B models in Q4 quantization for roughly half the cost of a Mac Studio.19
Economics: Total Cost of Ownership and ROI
A common misconception is that running local models is significantly more expensive than subscriptions due to hardware costs and electricity. However, a Total Cost of Ownership (TCO) analysis over a 5-year lifecycle reveals a different reality. Local deployment achieves cost parity with cloud services within 6-12 months for any organization or individual spending $500 or more per month on API access.24
The “Token Economics” Framework
For small teams, hardware is a major upfront expense (CapEx), but staffing and operational maintenance dominate the 3-year TCO.23 For home users, the calculation is simpler: the hardware replaces a $20/month subscription ($240/year) and provides a multi-purpose computer.21 Electricity costs for an Apple Silicon setup are negligible, estimated at $5-$10 per month even with high utilization.17 High-end NVIDIA setups are more expensive to operate, with dual-GPU towers adding $50-$200 to monthly utility bills.23

While the NVIDIA build appears more expensive, it offers value in “Token Velocity.” The RTX 5090 has a price-performance ratio of approximately $9.38 per token/second, whereas enterprise hardware like the H100 remains over $100 per token/second when amortized.15 For users generating millions of tokens per month for coding or content automation, the ROI on a local GPU rig is realized in less than six months compared to paying OpenAI or Anthropic for equivalent volume.24
Operational Realities: Pros and Cons
The decision to self-host is a trade-off between control and convenience. The landscape in 2026 has provided tools that significantly lower the barrier to entry, but the technical burden remains higher than using a web interface.
The Advantages of Self-Hosting
The primary motivation for local models is Absolute Sovereignty. Data residency is a legal requirement in sectors like healthcare (HIPAA) and finance, where cloud-based AI represents a catastrophic risk of data breach or model leakage.21 Local models operate entirely offline, providing continuity in remote locations or during internet outages.26
Furthermore, self-hosting provides Architectural Freedom. Users can customize the system prompt, adjust low-level parameters like temperature and top-p, and integrate models into complex agentic workflows using tools like MCP (Model Context Protocol) or OpenClaw.21 This eliminates the “vendor lock-in” where an application breaks because a provider updates their model or changes their API pricing.2
The Disadvantages and Risks
The most critical disadvantage is the Security Surface. As of 2026, researchers have identified 175,000 publicly exposed Ollama servers globally, many of which are being actively exploited by “LLMjacking” campaigns.31 Attackers scan for unauthenticated endpoints to steal compute resources for spam generation or cryptocurrency mining, often resulting in victim losses of thousands of dollars in electricity or cloud compute bills.31
Additionally, the Technical Debt of maintaining a local stack is non-trivial. Tools like Ollama often lack automated update mechanisms, requiring manual intervention to pull new models or patch vulnerabilities.23 Hardware failure, driver compatibility issues (particularly with NVIDIA), and memory leaks are common issues that require daily or weekly attention.17

Software Ecosystem and Tooling
In 2026, the software used to run LLMs has matured into three distinct tiers based on user needs.
CLI and Infrastructure: Ollama and LocalAI
Ollama is the de facto standard for developers. It functions as a background daemon that exposes an OpenAI-compatible API on localhost:11434.31 This allows any application designed for ChatGPT to be “redirected” to a local model with a single line of code.28 LocalAI provides a similar function but is optimized for Docker-first deployments and enterprise self-hosting of multiple model types.28
Graphical User Interfaces: LM Studio and Jan
For users who prefer a desktop application experience, LM Studio is the “Gold Standard” of 2026. It handles model discovery on Hugging Face, manages downloads, and provides a multi-model chat interface with full control over the system prompt.29 Jan is a privacy-focused alternative that emphasizes an offline-first assistant experience and integrates well with the emerging MCP ecosystem for tool-calling agents.28
Power User Tools: Text-Generation-WebUI and Unsloth
Researchers and power users typically rely on text-generation-webui (Oobabooga), which supports the widest variety of model backends (GGUF, EXL2, AWQ) and includes extensions for character roleplay and custom RAG.28 Unsloth has become an indispensable tool for users looking to perform local fine-tuning, as it allows for the creation of GGUF quantized models with significantly reduced memory overhead during the training process.34
Security Mitigation for Local Servers
Securing a local LLM instance is mandatory for anyone exposing their machine to the network. The consensus among security experts in 2026 includes the following standard protocols:
Network Isolation: The inference engine should bind to 127.0.0.1. If external access is required, it should be mediated through a VPN like Tailscale or WireGuard.32
Reverse Proxy and Authentication: Using a proxy like Nginx or Caddy with TLS termination prevents traffic sniffing. Implementing API key or OAuth 2.0 authentication ensures that only authorized clients can submit prompts.32
Sanitization and Validation: For public-facing agents, input sanitization is required to prevent “Prompt Injection” attacks where an attacker crafts a message that tricks the model into revealing system credentials or executing malicious code.4
Containerization: Running LLM runners inside Docker or Podman as a non-root user limits the potential for an “escape” vulnerability to compromise the host operating system.31
The Rise of Small Language Models (SLMs)
A critical second-order insight of 2026 is that the “best” way to use an LLM at home often involves using a Small Language Model (SLM) rather than a 70B+ behemoth. Models in the 1B to 14B range, such as Microsoft Phi-4 and Google Gemma 3, have achieved performance levels that meet or exceed GPT-3.5 and GPT-4o-mini on specific tasks.43
For over 80% of enterprise and personal tasks—such as text classification, summarization, and entity extraction—a 70B parameter model is “overkill”.43 An SLM like Phi-4 (14B) can run on a single RTX 4090 with latency under 50ms, enabling real-time interactions that are impossible with larger models.43 Furthermore, SLMs paired with LoRA (Low-Rank Adaptation) fine-tuning can outperform massive general-purpose models on domain-specific tasks, such as legal Q&A or medical transcript analysis.43

Future Outlook: Private AI and Autonomous Agents (2027-2030)
The sector is currently transitioning from “models as chatbots” to “models as agents.” By 2027, Gartner predicts that AI proficiency will be a baseline requirement for most roles, similar to Microsoft Office in the 1990s.46 This shift will emphasize the need for “Personal Data Vaults”—local, encrypted repositories of personal and professional data that only the user’s private LLM can access.46
The Agentic Revolution
By 2030, AI agents will transform from tools to autonomous partners capable of negotiating contracts, managing marketing strategies, and learning through physical world interactions.47 This autonomy necessitates local processing; an agent with the authority to negotiate on a user’s behalf cannot rely on a centralized cloud provider that may experience outages, change its terms of service, or leak sensitive negotiation strategies.26
The Hardware Convergence
Hardware will continue to move toward the “Blackwell Efficiency Singularity,” where the architectural improvements in GPUs and NPUs make massive model inference a standard feature of consumer electronics.34 We anticipate that by 2029, the distinction between a “GPU” and an “NPU” will blur, and 128GB of high-bandwidth unified memory will be the baseline for mid-range laptops.34 This will enable every user to run a private, “Elite” tier model natively, ending the era of centralized AI gatekeeping.
Crisis and Governance
The rapid progression of AI capabilities—described by some researchers as the “AI 2027 Roadmap”—suggests that by late 2027, AI systems will produce R&D breakthroughs faster than human researchers can follow.48 In this high-velocity environment, the risk of “model escape” or autonomous misuse will lead governments to impose strict regulations on centralized providers.48 Paradoxically, this will further drive users toward local, air-gapped systems where they can maintain control over their intelligence tools away from the reach of state or corporate “pause” commands.6
Conclusion: The Path Toward Sovereign Intelligence
The current analysis confirms that for users requiring reliability, privacy, and unrestricted capability, local LLM deployment is the superior strategy in 2026. Commercial models, while impressive in their raw scale, have become compromised by the twin pressures of fiscal optimization and ideological censorship. This has created a “tax” on intelligence—an alignment tax that degrades reasoning and a cost tax that degrades consistency.
The most effective home options right now are divided by budget: the refurbished Mac Studio for those requiring massive parameter counts and long context, and the RTX 5090 build for those prioritizing coding speed and high-throughput automation. For the budget-conscious, the AMD mini-PC and the base Mac Mini M4 offer realistic, capable entry points that provide better long-term ROI than cloud subscriptions.
As the sector moves toward 2030, the “Sovereign AI” movement will likely become the dominant paradigm for professional and private life. The transition from renting a centralized chatbot to owning a local autonomous agent is not merely a technical upgrade; it is a fundamental reclamation of digital agency in an age where intelligence has become the most valuable commodity. By building local infrastructure today, users are securing their place in a future where private, uncensored, and highly capable AI is the foundational layer of all human endeavor.
Works cited
Position: Fundamental Limitations of LLM Censorship Necessitate New Approaches, accessed April 6, 2026, https://proceedings.mlr.press/v235/glukhov24a.html
LLM Applications: Current Paradigms and the Next Frontier - arXiv, accessed April 6, 2026, https://arxiv.org/html/2503.04596v2
That Violates My Policies: AI Laws, Chatbots, and The Future of ..., accessed April 6, 2026, https://futurefreespeech.org/that-violates-my-policies-ai-laws-chatbots-and-the-future-of-expression/
Securing LLMs: Best Practices for Enterprise Deployment - ISACA, accessed April 6, 2026, https://www.isaca.org/resources/isaca-journal/issues/2024/volume-6/securing-llms
Censorship Is Not Deterring Global Adoption of Chinese AI - ChinaFile, accessed April 6, 2026, https://www.chinafile.com/reporting-opinion/features/censorship-not-deterring-global-adoption-of-chinese-ai
What Large Language Models Do Not Talk About: An Empirical Study of Moderation and Censorship Practices - arXiv, accessed April 6, 2026, https://arxiv.org/html/2504.03803v1
The humanities must have a role in overseeing AI ‘censorship’, accessed April 6, 2026, https://www.timeshighereducation.com/opinion/humanities-must-have-role-overseeing-ai-censorship
Open Source vs Proprietary LLMs: Complete 2025 Benchmark ..., accessed April 6, 2026, https://whatllm.org/blog/open-source-vs-proprietary-llms-2025
Best AI Models April 2026: Ranked by Benchmarks, accessed April 6, 2026, https://www.buildfastwithai.com/blogs/best-ai-models-april-2026
Best Open-Source LLM Models: Flow Benchmark Results Revealed - Recursive AI, accessed April 6, 2026, https://recursiveai.co.jp/news/best-open-source-llm-models
Dolphin Llama 3 70B Free Chat Online - Skywork, accessed April 6, 2026, https://skywork.ai/blog/models/dolphin-llama-3-70b-free-chat-online/
Top 10 LLMs with No Restrictions in 2026 - Apidog, accessed April 6, 2026, https://apidog.com/blog/llms-no-restrictions/
7 Best GPU for LLM in 2026 (Including Local LLM Setups) - Fluence Network, accessed April 6, 2026, https://www.fluence.network/blog/best-gpu-for-llm/
Best Local LLMs to Run On Every Apple Silicon Mac in 2026 - ApX Machine Learning, accessed April 6, 2026, https://apxml.com/posts/best-local-llms-apple-silicon-mac
The Best GPUs for Local LLM Inference in 2025 | LocalLLM.in, accessed April 6, 2026, https://localllm.in/blog/best-gpus-llm-inference-2025
Local LLM Hardware Guide 2025: GPU Specs & Pricing | Introl Blog, accessed April 6, 2026, https://introl.com/blog/local-llm-hardware-pricing-guide-2025
Apple MLX vs. NVIDIA: How local AI inference works on the Mac - Markus Schall, accessed April 6, 2026, https://www.markus-schall.de/en/2025/11/apple-mlx-vs-nvidia-how-local-ki-inference-works-on-the-mac/
I Almost Bought an RTX 5090. Then Apple’s Unified Memory Changed My Mind, accessed April 6, 2026, https://ksingh7.medium.com/i-almost-bought-an-rtx-5090-then-apples-unified-memory-changed-my-mind-83eb964e930b
Mac Mini M4 vs AMD Mini PCs for Local AI: A Hardware Buyer’s Guide by Budget Tier, accessed April 6, 2026, https://medium.com/@tentenco/mac-mini-m4-vs-amd-mini-pcs-for-local-ai-a-hardware-buyers-guide-by-budget-tier-46955a45b4c5
M3 Ultra vs RTX 5090 : r/apple - Reddit, accessed April 6, 2026, https://www.reddit.com/r/apple/comments/1jm4sc0/m3_ultra_vs_rtx_5090/
Best Mac for AI in 2026: Run Local LLMs on a Budget - RefurbMe, accessed April 6, 2026, https://www.refurb.me/blog/best-mac-for-ai
3090 vs mac choice : r/LocalLLaMA - Reddit, accessed April 6, 2026, https://www.reddit.com/r/LocalLLaMA/comments/1n5agg5/3090_vs_mac_choice/
Ollama Pricing 2026: Plans, Costs & TCO - CheckThat.ai, accessed April 6, 2026, https://checkthat.ai/brands/ollama/pricing
The Complete Guide to Running LLMs Locally: Hardware, Software, and Performance Essentials - IKANGAI, accessed April 6, 2026, https://www.ikangai.com/the-complete-guide-to-running-llms-locally-hardware-software-and-performance-essentials/
Energy Cost of using MacStudio : r/LocalLLaMA - Reddit, accessed April 6, 2026, https://www.reddit.com/r/LocalLLaMA/comments/1rpee4x/energy_cost_of_using_macstudio/
Open-Source LLMs vs Proprietary Models: The 2025 Showdown - Diggibyte, accessed April 6, 2026, https://diggibyte.com/open-source-llms-vs-proprietary-models/
“Best AI Workstation Processors 2025 – AMD Ryzen AI Max Pro vs Intel for Local AI”, accessed April 6, 2026, https://www.techoutlet.eu/en/blog/post/best-ai-workstation-processors-2025-amd-ryzen-ai-max-pro-vs-intel-for-local-ai
Top 5 Local LLM Tools and Models in 2026 - DEV Community, accessed April 6, 2026, https://dev.to/lightningdev123/top-5-local-llm-tools-and-models-in-2026-1ch5
Unlock Local AI Tools: Explore Ollama for Privacy & Control 2026 - Ruhani Rabin, accessed April 6, 2026, https://www.ruhanirabin.com/best-local-ai-tools-for-running-large-language-models/
Ollama vs LM Studio vs GPT4all vs Jan (2026) - YouTube, accessed April 6, 2026,
Researchers Find 175,000 Publicly Exposed Ollama AI Servers Across 130 Countries, accessed April 6, 2026, https://thehackernews.com/2026/01/researchers-find-175000-publicly.html
Exposed Ollama Servers: Security Risks of Publicly Accessible LLM Infrastructure, accessed April 6, 2026, https://securityboulevard.com/2026/03/exposed-ollama-servers-security-risks-of-publicly-accessible-llm-infrastructure/
Understanding and Securing Exposed Ollama Instances - UpGuard, accessed April 6, 2026, https://www.upguard.com/blog/understanding-and-securing-exposed-ollama-instances
How to Run Your Own Local LLM — 2026 Edition — Version 1 | HackerNoon, accessed April 6, 2026, https://hackernoon.com/how-to-run-your-own-local-llm-2026-edition-version-1
LLMs Explained: Open-Source Vs Proprietary AI Models - AceCloud, accessed April 6, 2026, https://acecloud.ai/blog/open-source-vs-proprietary-llms/
AI Privacy Risks & Mitigations – Large Language Models (LLMs) - European Data Protection Board, accessed April 6, 2026, https://www.edpb.europa.eu/system/files/2025-04/ai-privacy-risks-and-mitigations-in-llms.pdf
Top 5 Local LLM Tools and Models in 2026 - Pinggy, accessed April 6, 2026, https://pinggy.io/blog/top_5_local_llm_tools_and_models/
Best Local LLM Runners (2026) — Compare & Vote | Price Per Token, accessed April 6, 2026, https://pricepertoken.com/directory/local-llm-runners
My self-sovereign / local / private / secure LLM setup, April 2026 - Vitalik Buterin’s website, accessed April 6, 2026, https://vitalik.eth.limo/general/2026/04/02/secure_llms.html
15 Best Lightweight Language Models Worth Running in 2026, accessed April 6, 2026, https://blog.premai.io/best-lightweight-language-models-worth-running/
OpenClaw Security: Best Practices For AI Agent Safety - DataCamp, accessed April 6, 2026, https://www.datacamp.com/tutorial/openclaw-security
Top 9 LLM Security Best Practices - Check Point Software, accessed April 6, 2026, https://www.checkpoint.com/cyber-hub/what-is-llm-security/llm-security-best-practices/
Small Language Models: Phi-4 vs Gemma 3 vs Llama 3.3 — Enterprise Edge AI [2026], accessed April 6, 2026, https://www.meta-intelligence.tech/en/insight-slm-enterprise
Best Small Language Models (March 2026): Run AI on 4GB RAM — Phi-4, Gemma 3, Qwen 3, accessed April 6, 2026, https://localaimaster.com/blog/small-language-models-guide-2026
The Best Open-Source Small Language Models (SLMs) in 2026 - BentoML, accessed April 6, 2026, https://www.bentoml.com/blog/the-best-open-source-small-language-models
Gartner forecasts how AI will transform data and analytics by 2030 - Digit.fyi, accessed April 6, 2026, https://www.digit.fyi/gartner-forecasts-how-ai-will-transform-data-and-analytics-by-2030/
The AI Agents Of 2030: What’s Coming Next? - YouTube, accessed April 6, 2026,
AI Expert Predictions for 2027: A Logical Progression to Crisis | Center for AI Policy | CAIP, accessed April 6, 2026, https://www.centeraipolicy.org/work/ai-expert-predictions-for-2027-a-logical-progression-to-crisis
On-Premise vs Cloud: Generative AI Total Cost of Ownership (2026 Edition) - Lenovo Press, accessed April 6, 2026, https://lenovopress.lenovo.com/lp2368-on-premise-vs-cloud-generative-ai-total-cost-of-ownership-2026-edition
NPU Comparison 2026: Intel vs Qualcomm vs AMD vs Apple | Local AI Master, accessed April 6, 2026, https://localaimaster.com/blog/npu-comparison-2026
Gartner Predicts AI Agents Will Reduce The Time It Takes To Exploit Account Exposures by 50% by 2027, accessed April 6, 2026, https://www.gartner.com/en/newsroom/press-releases/2025-03-18-gartner-predicts-ai-agents-will-reduce-the-time-it-takes-to-exploit-account-exposures-by-50-percent-by-2027
·
27 MAR

Diplomacy as Alibi: When “Negotiations” Become the Pretext
·
28 MAR

The Evolution, Architecture, and Systemic Constraints of Large Language Models: A Comprehensive Analysis of Research Integrity and Safety Protocols
