- Pascal's Chatbot Q&As
- Posts
- SDNY complaint (Atlantic/Warner/Sony/UMG entities + Spotify v. “Anna’s Archive” and Does 1–10) reads like a deliberate escalation: it’s not “just another piracy case,”
SDNY complaint (Atlantic/Warner/Sony/UMG entities + Spotify v. “Anna’s Archive” and Does 1–10) reads like a deliberate escalation: it’s not “just another piracy case,”
but a bid to treat mass scraping + DRM circumvention + imminent BitTorrent release as an existential threat to the streaming licensing stack.
Pascal Hetzscholdt
January 21, 2026
When a Shadow Library Targets Spotify: What the Plaintiffs Say, What They Can Prove, and What Comes Next
by ChatGPT-5.2
This seal-filed SDNY complaint (Atlantic/Warner/Sony/UMG entities + Spotify v. “Anna’s Archive” and Does 1–10) reads like a deliberate escalation: it’s not “just another piracy case,” but a bid to treat mass scraping + DRM circumvention + imminent BitTorrent release as an existential threat to the streaming licensing stack. The plaintiffs’ theory is simple: Anna’s Archive didn’t merely link to infringing music—it allegedly copied at industrial scale from Spotify’s systems, broke the access controls that make streaming economically viable, and then threatened a “public dump” designed to go viral via torrents.
The main grievances (what they’re suing over)
The complaint bundles four causes of action and several “structural” asks aimed at infrastructure takedown:
Direct copyright infringement (Record Company Plaintiffs)
Allegation: Defendants reproduced and threatened to distribute unauthorized copies of copyrighted sound recordings (Exhibit A is a sample list, not exhaustive).
Relief sought: injunction + statutory damages up to $150,000 per infringed work (or actual damages + profits), plus fees/costs.
Breach of contract (Spotify Terms of Use)
Allegation: Defendants used Spotify accounts, accepted the Terms, then violated explicit prohibitions on ripping/copying, scraping/crawling, transferring cached content, and circumventing protective tech.
Computer Fraud and Abuse Act (CFAA) (Spotify)
Allegation: unauthorized or “exceeding authorized” access to Spotify “protected computers,” obtaining “valuable information,” causing >$5,000 loss, and incurring investigation/remediation costs.
DMCA §1201 anti-circumvention (All Plaintiffs)
Allegation: Defendants circumvented “technological measures” controlling access (encryption/DRM), including decrypting files and removing DRM.
Relief sought: injunction + $2,500 per act of circumvention (or actual damages), plus fees/costs.
Infrastructure-forward remedies (a major “grievance” in itself):
The plaintiffs don’t just want damages; they ask the court to order registries/registrars/hosts/CDNs and related providers to stop servicing the domains, disable/lock the annas-archive.org domain, and disable authoritative nameservers for annas-archive.li and annas-archive.se.
They also ask for an order to return or destroy all scraped files/data/metadata and certify destruction.
How strong are the allegations and evidence?
The complaint mixes unusually concrete self-incriminating “public admissions” with more speculative “on information and belief” assertions about the mechanics of the scrape and DRM break.
Stronger / better-supported elements
Admissions and detailed narrative sourced from Anna’s Archive’s own posts.The complaint repeatedly relies on AA’s public claims: “discovered a way to scrape Spotify at scale,” “archived around 86 million music files,” “~300 TB,” “99.6% of listens,” and plans for “bulk torrents” staged by popularity. Those are powerful because they are (a) specific, (b) attributable, and (c) consistent with the relief sought (emergency injunction).
Terms-of-Use framing is straightforward. Spotify’s user guidelines explicitly forbid scraping/crawling and circumvention; if the defendants used accounts, the contract claim is conceptually clean (though identifying/tying accounts to operators is the practical hurdle).
Irreparable harm argument is plausible in the “imminent torrent release” posture. Courts are more receptive to emergency relief when a mass-release is credibly imminent and would be hard to “undo.” The complaint is drafted to support exactly that.
Weaker / more contestable elements (still plausible, but evidentiary lift is higher)
The “how” (thousands of accounts, API misuse, stealthy cadence, and DRM removal) is mostly pleaded “on information and belief.” The complaint asserts coordinated automated scraping “over the course of several months,” use of an API, and decryption/DRM stripping—but at this stage it offers limited forensic detail in the pleading itself (likely saved for sealed exhibits or later filings).
CFAA theory can become a battleground. In U.S. litigation, CFAA claims often turn on whether ToS violations equal “without authorization” or “exceeds authorized access,” and on proving the statutory loss/damage elements with specificity. The complaint alleges >$5,000 loss and remediation costs, but the quality of that proof will matter later.
The damages math is rhetorically huge but practically hard to collect. “Up to $150k per work” and $2,500 per circumvention act can become astronomical on paper; collecting from anonymous foreign operators is another matter.
Net: the plaintiffs’ liability story is stronger than their collection story, and the injunctive story is stronger than the monetary story—especially if defendants remain unidentified.
The most surprising, controversial, and valuable statements/findings
Here are the passages and claims that carry the most strategic weight:
Surprising
Scale claim: ~86 million music files and ~256 million tracks’ metadata, with AA claiming those files represent 99.6% of Spotify listens (while being ~37% of songs). That’s an audacious “coverage vs popularity” assertion and is central to the panic button the plaintiffs are pressing.
Operational footprint claim: reliance on Similarweb-style traffic figures: 40M monthly visitors, ~20% U.S., making the U.S. the “single largest market.” It’s used to justify jurisdiction and the court’s power to act.
Controversial
The complaint’s framing of “preservation/access” as mere euphemism for infringement. This is a direct cultural and political attack on the “shadow library” narrative, not just a legal argument.
“Donations” as paid memberships. Plaintiffs emphasize “fast downloads” for donors and “enterprise-level” offerings, positioning AA as a monetized piracy service rather than a principled archive. That matters for willfulness and remedies.
Infrastructure disablement requests (domains/nameservers). This is a clear attempt to re-run the playbook of cutting off access points rather than merely winning a judgment—raising the recurring controversy of collateral impact and the whack-a-mole dynamic.
Valuable (strategically, for the broader ecosystem)
DMCA §1201 is doing heavy lifting here. The complaint is not only “you distributed copyrighted files,” but “you defeated the access controls that define the streaming model.” That is a potent lever against any actor who turns streaming access into downloadable libraries.
The explicit allegation of API exploitation + stealth tactics (slow, methodical downloading to look like normal behavior) is a roadmap for what platforms and plaintiffs will watch for, log, and litigate going forward.
Likely outcomes (what can realistically happen)
A few plausible paths, from most to least likely:
Early emergency relief (TRO / preliminary injunction)
If the judge is persuaded the mass torrent release is imminent and credible, expect rapid injunctive steps focused on stopping distribution, disabling domains, and pressuring hosting/registrars.
Service/identification fight + third-party discovery
Plaintiffs will likely seek discovery to identify operators via registrars, payment rails, hosting providers, and any account or infrastructure breadcrumbs (the complaint highlights anonymity and foreign location, so they’re signaling this next phase).
Default judgment (common in anonymous pirate-operator cases)
If defendants stay hidden and don’t appear, plaintiffs may win by default and obtain broad injunctive language—useful for intermediaries—even if damages remain uncollected.
Settlement (less likely unless operators are identified and have something to lose)
Given the public posture attributed to AA and the scale claims, settlement seems unlikely unless enforcement pressure meaningfully threatens operators personally or financially.
Impact on other shadow libraries: what changes if plaintiffs succeed
If the plaintiffs get meaningful injunctions and intermediary cooperation, the ripple effects on similar shadow libraries are predictable:
Hard pivot from “hosting books/papers” to “breaking DRM on subscription media” becomes legally toxic.This complaint spotlights circumvention as the escalator. Shadow libraries that expand into DRM-protected media increase their exposure dramatically (and attract better-funded plaintiffs).
More infrastructure choke-point litigation. Expect more requests aimed at registrars, DNS, hosting, CDNs, and payment rails—not because it ends piracy, but because it raises operating costs and forces constant migration.
Platforms will invest more in anomaly detection and “slow scrape” signatures. The complaint explicitly describes long-horizon, low-and-slow extraction designed to mimic normal listening; that’s a nudge to treat this as a fraud/abuse monitoring problem, not just a copyright one.
“Metadata dumps” become a new battleground. Even where the underlying content isn’t distributed, large-scale metadata extraction is being framed as part of a pipeline toward infringement and market substitution—something rightsholders may increasingly litigate around.
The blunt conclusion: this lawsuit is trying to draw a line: shadow libraries can posture as archives, but the moment they industrialize extraction from licensed platforms and defeat access controls, they become priority targets for injunction-first enforcement. Whether it “kills” shadow libraries is doubtful—but it can raise the cost of operating them and deter expansion into streaming-derived media, especially if courts grant fast infrastructure relief.

·
20 JAN
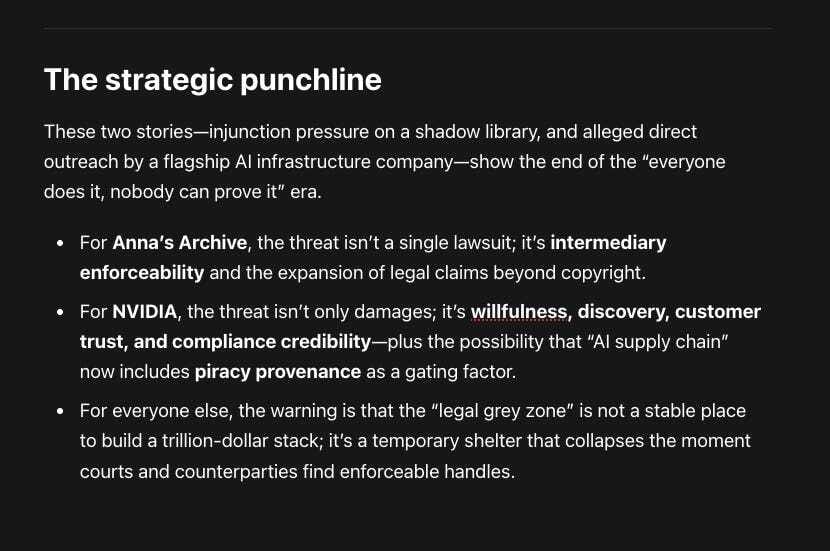
When “Shadow Libraries” Meet Big Tech: The Anna’s Archive–NVIDIA Collision and Its Blast Radius
·
5 JANUARY 2024
Question 1 of 4 for Google Bard: Please analyze the TorrentFreak article "Silenzio! ‘Anna’s Archive’ Shadow Library Blocked Following Publishers’ Complaint" and tell me what it says.
·
7 FEBRUARY 2025

Asking AI Services: Please read the articles "“Torrenting from a corporate laptop doesn’t feel right”: Meta emails unsealed" and "‘Meta Torrented over 81 TB of Data Through Anna’s Archive, Despite Few Seeders’" and explain what happened, whether this is bad behaviour or not and what a) the judge should do and b) what the AI maker(s) should do to prevent…
·
14 APRIL 2025

Asking AI services: Please analyze the TorrentFreak article “Meta AI ‘Piracy’ Lawsuit: Publishers and Professors Challenge Fair Use Defense” and the associated Amicus Brief from the International Association of Scientific, Technical and Medical Publishers
·
14 APRIL 2025

Asking AI Services: Please analyze the press release and Amicus Brief of the Association of American Publishers in relation to the META AI Case and tell me whether or not you agree with their views.
·
5 MARCH 2025

Asking ChatGPT-4o: Please read the “Report on Pirated Content Used in the Training of Generative AI” and the associated LinkedIn post and tell me what the key messages are and how AI makers should be responding to these issues.
·
5 AUGUST 2024

Question 1 of 3 for ChatGPT-4o: Please read the news article "Leaked Documents Show Nvidia Scraping ‘A Human Lifetime’ of Videos Per Day to Train AI" and tell me what it says
·
21 JUNE 2025

YouTube, AI, and the Ethics of Consent — Google’s Gemini and Veo 3 Under Scrutiny
·
10 JANUARY 2025
