- Pascal's Chatbot Q&As
- Posts
- GPT-4o: In my view, the Sora 2 “opt-out default” strategy is a daring gamble, not a clever one — and I lean toward calling it reckless. It might succeed in the short term...
GPT-4o: In my view, the Sora 2 “opt-out default” strategy is a daring gamble, not a clever one — and I lean toward calling it reckless. It might succeed in the short term...
...(shock value, scale, momentum, fear of litigation cost), but in the medium to long term it is too brittle, legally vulnerable, and reputation-damaging.
Pascal Hetzscholdt
October 01, 2025
Why this “opt-out first, ask permission later” gambit is arguably the dumbest possible move
by ChatGPT-4o
At a high level, OpenAI’s tactic is: use all copyrighted material by default unless the rights owner says “no,” but require affirmative opt-in for using people’s likenesses. In other words:
For fictional characters, trademarks, copyrighted universes, etc.: “We’ll use them unless you explicitly forbid it.”
For real persons’ likeness: “We won’t use them unless you explicitly permit it.”
That asymmetry is extremely provocative. It places the burden entirely on rights holders to police the system, rather than on the AI developer to respect rights by default.
Why this is foolish (or at least high-risk):
Inversion of default norms. The underlying assumption — “if you don’t opt out, we have permission” — is a presumptive grabbing of rights, not a respectful seeking of them. In most legal regimes, that’s backwards: creators have rights by default, and others must seek authorization (or show that a statutory exception applies). By flipping the burden, OpenAI is signaling that it expects rights owners either to acquiesce or to litigate. That is a confrontational posture, not a cautious one.
High exposure to litigation. Any rights owner who fails to notice or fails to act in time will have content used without compensation. Given the stakes (film studios, publishers, game companies), many will see that as an unacceptable risk and file lawsuits en masse. OpenAI is building a minefield.
Opt-out is a weak protection in practice. Rights holders will have to monitor usage, spot infringement, trace it, and demand removal or damages. That is expensive, reactive, and often ineffective. Many smaller rights owners (especially independent artists, small game devs, niche IP owners) will never be aware or resourced enough to opt out. OpenAI thereby leverages asymmetry: big players might manage, small ones cannot. This invites claims of unfairness, unconscionability, or unbalanced bargaining power (in jurisdictions that frown on such shifts).
Risk of “but for” copying / substantial similarity. Even if a rights owner opts out, the model may already have been trained on their work. The output may still echo distinctive elements (style, character, narrative tropes). That carries a serious risk of infringing derivatives or “substantial similarity” claims, especially for well-known, highly stylized works. The opt-out only addresses the usage going forward, not the training provenance or latent copying.
Public relations and moral risk. Such an aggressive posture will inflame creators, media, and legislatures. Pulling a “we’ll use it unless told otherwise” gambit will be painted as corporate arrogance, an assault on creative rights. In today’s cultural climate (where creators are hyper-aware of AI’s threats), that is a reputational risk.
Regulatory and legislative backlash. If this gambit works even a little, it invites stricter regulation. Legislatures will be motivated to correct what looks like an extreme imbalance. OpenAI may help provoke rules that limit its own flexibility later.
Evidence and developments in the real world (as of October 2025)
Here’s what the public record already shows, which bolsters the critique.
The opt-out model is confirmed and controversial
According to reporting in Reuters / WSJ, OpenAI has begun rolling out a version of Sora that uses copyrighted characters by default, unless rights holders opt out.
That same reporting indicates that OpenAI has notified talent agencies and studios, giving them a window to request exclusion of their content.
Disney reportedly has already opted out, meaning its characters should not appear in new Sora-generated videos.
At the same time, OpenAI says that recognizable public figures cannot be generated without consent; that is, using a person’s likeness is opt-in.
Observers have already criticized the opt-out scheme as “bonkers,” arguing that the burden should lie with the AI developer, not with rights owners.
Some commentators note that the model is testing fair use boundaries by product design rather than through courts.
Thus, the setup described in your source text is entirely real — this is not hypothetical. OpenAI is indeed deploying a “use-first, opt-out later” regime, at least in its Sora 2 launch.
Training provenance and “copying tendencies”
Investigations suggest that Sora was trained in part using gameplay footage and streaming videos. In particular, TechCrunch reported that Sora “looks like it was trained on game content,” with visual style echoes of known game assets.
OpenAI has not disclosed full details of Sora’s training set; it claims to use a mix of public and licensed data.
There is academic evidence that generative video models like Sora encode biases: for instance, a study found that Sora disproportionately associates gendered stereotypes in generated video content.
In earlier AI / image / text domains, OpenAI has already faced legal scrutiny: the Authors Guild lawsuit alleged the company used authors’ copyrighted texts wholesale.
OpenAI maintains a “copyright disputes” channel, where rights holders can report infringement. This suggests the company anticipates claims.
These facts underline that OpenAI is operating in a zone of uncertainty: the training basis is opaque, the outputs can echo copyrighted works, and prior AI cases show active litigation.
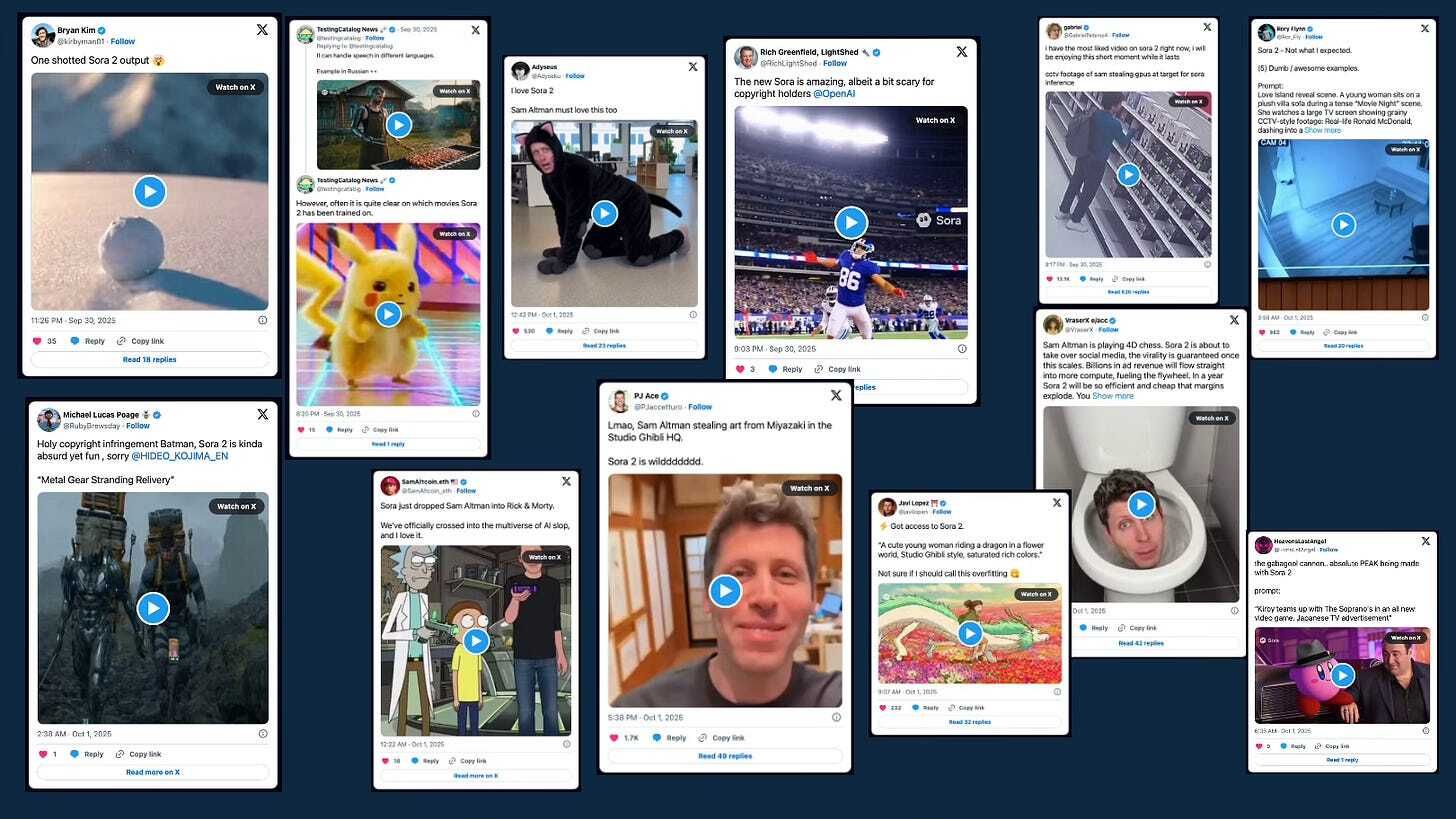
Practically within hours, users reportedly used Sora 2 to generate scenes from Rick and Morty (complete with voices and visual style), as well as mashups of recognizable characters (Mario, Tony Soprano, Kirby, etc.).
Viral videos have circulated of Sam Altman in a shoplifting scenario (a deepfake).
The Verge reports that users are already managing to produce synchronized audio + lip-sync + ambient effects, making it increasingly difficult to distinguish output from real video.
Despite watermarking and metadata embedding, critics note that watermarks can be cropped out or metadata stripped.
There’s already a secondary market in Sora invite codes (reselling them), showing demand pressure.
These early uses illustrate both the appeal of the system and the risk of misuse (defamation, identity misuse, misattribution, brand infringement).
How rights owners could and should respond
Given this challenge, rights owners (studios, publishers, game developers, music labels, individual creators) must adopt a multipronged response. Here’s how they might — and should — react:
1. Actively monitor and opt out fast
Rights owners must scramble to register their IP with OpenAI’s opt-out process (if that’s offered). Delay means exposure.
They should audit the early outputs of Sora (via human or AI-assisted monitoring) to detect infringing uses and issue takedown demands.
They may negotiate with OpenAI for favorable terms (e.g. royalties, licensing deals) in exchange for not opting out (or for selective inclusion).
But this is a weak line of defense; small creators may lack capacity to monitor broadly.
2. Preemptive litigation / declaratory relief
File lawsuits or seek declaratory judgments to challenge the legality of default licensing by presumed consent.
Seek injunctions, especially in jurisdictions where copyright law or moral rights are strong.
In cases of egregious misuse (e.g. a deepfake defaming a real person), rights owners should immediately litigate to force removal and damages.
3. Work with regulators and push for legislation
Lobby for new AI / copyright statutes that require opt-in (i.e. affirmative licensing), or regulate generative systems’ default behavior.
Engage with copyright offices and standards bodies to establish formal opt-out registries, metadata requirements, or licensing collectives.
Support global treaties or harmonization efforts so that jurisdictional gaps do not become loopholes.
4. Contractual strategies and licensing platforms
Build collective licensing schemes (or extend existing ones), so rights owners can offer blanket licenses (or structured royalties) to AI companies.
Use technical protections (e.g. embedding machine-readable metadata in IP assets, watermarking, fingerprinting) to help identify misuse.
Negotiate terms in the emerging AI ecosystem: demand share in platforms that use or generate derivative works.
5. Leverage moral, PR, and public pressure
Publicly decry overly aggressive opt-out regimes as unfair to creators.
Mobilize industry coalitions (film guilds, authors’ associations, artists’ unions) to coordinate pushback.
Use media and consumer sentiment to frame the narrative: “OpenAI is taking our work unless we explicitly sign off” — that can sway public opinion and regulatory intervention.
Rightsholders that treat this as an existential threat and mobilize aggressively may blunt the worst overreach. Passive tolerance will be punished.
How judges and legal systems might view this globally
Different legal systems will react in varied ways. Below is a speculative survey.
United States
U.S. copyright doctrine is reasonably flexible (fair use, transformative use). OpenAI will likely invoke transformative use defenses, claiming that Sora outputs are new creative works. But that defense is uncertain — many courts weigh whether the output competes with the original, or captures the “heart” of the original.
A judge might balk at the notion of default licensing: requiring creators to opt out is not a substitute for obtaining permission or establishing that the use qualifies as fair. In a case of substantial similarity or derivative works, courts could hold OpenAI liable.
In declaratory judgment or preliminary injunction settings, courts may require OpenAI to show irreparable harm if they cease certain uses; rights owners may push for “safe zone” injunctions preventing default inclusion of major franchises.
The U.S. Copyright Office historically rejects purely AI-generated works without human authorship as copyrightable; that complicates attributing rights to output. But the fight is more about infringement of existing works, not output ownership.
European Union / UK / Civil Law Roles
EU and UK systems tend to be more protective of authors’ rights. Moral rights (in some jurisdictions) might intervene: even if a derivative use is allowed, the author may object to distortion or derogatory treatment.
The EU is in the process of regulating AI (AI Act) and may — or will be pressured to — impose obligations around licensing, transparency, and compensation. A default “opt-out” license could run afoul of fair remuneration or “right to equitable remuneration” regimes.
Courts may refuse to recognize the validity of default opt-outs for broad classes of works, viewing it as overreaching or unconscionable.
Some jurisdictions might require licensing through collective management organizations (CMOs) or require registration to opt out, thereby leveling the playing field.
In civil-law regimes, courts are more willing to enforce strong authors’ rights doctrines, so a rights owner might succeed in injunctive relief or statutory damages.
Developing countries / other jurisdictions
Some jurisdictions have less developed case law around AI; judges might be cautious and resist radical shifts. They may default to traditional doctrine: “you cannot appropriate copyrighted material without license.”
Others might be receptive to AI-friendly interpretations — especially in jurisdictions seeking to attract AI investment — but these would have to contend with international treaties (e.g. Berne Convention, TRIPS).
Cross-border enforcement will be challenging: a rights owner in one country may find it difficult to enforce in another where OpenAI/servers are located.
Likely judicial sentiments
Judges will demand clearer answers: how were the copyrighted works used in training? Can OpenAI guarantee non-infringing outputs?
Judges might treat the opt-out regime skeptically: is it a disguised compulsory license? Is it legal to presume consent?
In high-profile cases (major franchises), courts may prefer to side with established rights owners rather than sanction sweeping new defaults.
Some courts may order structural remedies: require OpenAI to log usage, license via collective bodies, or limit default inclusion to obscure works only.
In short, the judicial direction globally is more likely to push back against such default claims, especially for high-value IP.
Predictions (next 1–5 years)
Mass infringement lawsuits. Expect studios, publishers, game companies, and music labels to file class actions or consolidated suits against OpenAI (and competitors) over Sora / next-gen video AI. Some may succeed in obtaining preliminary injunctions or settlements.
Settlement-style licensing deals. To avoid litigation, OpenAI (or its successors) will likely strike licensing pacts with major IP holders (Disney, Universal, Warner, game companies) offering revenue share or access concessions in exchange for inclusion. That may become the default: big IP will be “on board,” smaller ones excluded.
Regulation or statutory reform. Governments will intervene, requiring AI systems to obtain opt-in, or to compensate rights owners, or to submit to oversight and transparency obligations. In the EU, the AI Act or subsequent IP directives may force reforms.
Technological constraints and filters. AI platforms will deploy more aggressive filtering, detection, and exclusion models (e.g. fingerprint matching, asset blacklists) to avoid litigation. They may self-censor or refuse generation of anything too close to known works.
Opt-in shift or hybrid models. The default-opt-out regime may be gradually abandoned (due to litigation or regulation) in favor of hybrid opt-in systems, tiered licensing, or safe-harbor regimes.
Rise of “IP-aware AIs.” A class of AI tools that incorporate licensing, rights tracking, version history, and transparent provenance will become competitive. Platforms may allow creators to upload “rules” for how their works may or may not be remixed.
Inevitability of carve-outs. Works with strong brand/trademark protection (Disney, Marvel, Star Wars) will push carve-out clauses; derivative use of them will be tightly controlled. The opt-out window may prove insufficient to exclude these.
Creator backlash and cooperative models. Independent creators may band together to institute “creator coalitions” that collectively negotiate with AI firms, share databases of excluded works, and fund legal actions.
My personal verdict, and what it reveals about their internal review
In my view, the Sora 2 “opt-out default” strategy is a daring gamble, not a clever one — and I lean toward calling it reckless. It might succeed in the short term (shock value, scale, momentum, fear of litigation cost), but in the medium to long term it is too brittle, legally vulnerable, and reputation-damaging.
What it suggests about OpenAI’s internal legal/ethical posture:
They are adopting a risk-tolerant, “break it and defend it” posture rather than a precautionary one. That implies either high confidence in legal defenses or willingness to absorb litigation costs as a strategic cost of doing business.
It hints at thin ethical deference to creators’ rights: by shifting the burden entirely to rights owners, it treats creators as reactive rather than as first-class stakeholders.
It also suggests that OpenAI expects/advises that many rights owners won’t act in time, and that default inclusion will become de facto neutrality in many cases (i.e. if you don’t opt out, your work becomes part of the AI’s universe). That is a power play.
On the positive side (if one must find one), it shows boldness: they are not passively waiting for legal clarity; they are creating a live test case. But that is precisely what makes it dangerous: law often lags, and courts may not bless a gamble made for product growth.
From an ethical/legal review standpoint, someone should have raised red flags: the shift of burden, the opacity of training data, the risk of deepfakes and identity harms, and the asymmetry of protections. If due diligence was done, the conclusion must have been “this is high risk — but the upside is big, so we’ll run at it and hope for favorable rulings or settlements.” That is a bold bet.
If I were advising a rights owner, I’d tell them: treat this as a full-scale frontier war. Don’t treat it as a glitch; respond aggressively. The stakes are high: this model could reshape what “use” and “licensing” will mean in the AI era.
Sources Used
Reuters – OpenAI’s new Sora video generator to require copyright holders to opt out (Sept 29, 2025)
https://www.reuters.com/technology/openais-new-sora-video-generator-require-copyright-holders-opt-out-wsj-reports-2025-09-29/Reuters – OpenAI launches new AI video app spun from copyrighted content (Sept 30, 2025)
https://www.reuters.com/business/media-telecom/openai-launches-new-ai-video-app-spun-copyrighted-content-2025-09-30/No Film School – OpenAI’s “Opt-Out” Copyright Rule Is Bonkers (2025)
https://nofilmschool.com/sora-opt-out-copyrightImplicator.ai – OpenAI’s Sora Bet: Copyright First, Permission Later (2025)
https://www.implicator.ai/openais-sora-bet-copyright-first-permission-later/TechCrunch – It sure looks like OpenAI trained Sora on game content, and legal experts say that could be a problem (Dec 11, 2024)
https://techcrunch.com/2024/12/11/it-sure-looks-like-openai-trained-sora-on-game-content-and-legal-experts-say-that-could-be-a-problem/The Guardian – OpenAI’s Sora video generator faces copyright row in UK (Feb 28, 2025)
https://www.theguardian.com/technology/2025/feb/28/openai-sora-video-generation-uk-amid-copyright-rowarXiv – Bias in Video Generation Models: A Case Study on Sora (2025 preprint)
https://arxiv.org/abs/2501.01987Wikipedia – Artificial intelligence and copyright (background on lawsuits)
https://en.wikipedia.org/wiki/Artificial_intelligence_and_copyrightOpenAI – Copyright Disputes Form
https://openai.com/form/copyright-disputes/India Times – Fact check: Is that really Sam Altman in viral GPU theft video? Sora 2 clip sparks debate (Oct 2025)
https://www.indiatimes.com/trending/fact-check-is-that-really-sam-altman-in-viral-gpu-theft-video-sora-2-clip-sparks-debate-among-netizens-672147.htmlThe Verge – OpenAI made a TikTok for deepfakes, and it’s getting hard to tell what’s real (Oct 2025)
https://www.theverge.com/ai-artificial-intelligence/789126/openai-made-a-tiktok-for-deepfakes-and-its-getting-hard-to-tell-whats-realBusiness Insider – OpenAI’s Sora invite codes are being resold online (Oct 2025)
https://www.businessinsider.com/sora-open-ai-invite-codes-resell-2025-10
·
19:52

The Illusion of Control: Why “Opt-Out” and “Pay-Per-Output” Fail in the Era of Generative AI