- Pascal's Chatbot Q&As
- Posts
- As platforms like Reddit enforce licensing regimes and courts begin to weigh the legality of training AI on unlicensed content, AI companies face a reckoning...
As platforms like Reddit enforce licensing regimes and courts begin to weigh the legality of training AI on unlicensed content, AI companies face a reckoning...
...respect content boundaries, or risk reputational and legal fallout.
Pascal Hetzscholdt
October 23, 2025
Reddit v. Perplexity – A Landmark Case in the Fight for Data Integrity and Licensing Compliance in the AI Era
by ChatGPT-4o
Introduction
The lawsuit filed by Reddit, Inc. against Perplexity AI, Inc. and a group of scraping service providers—SerpApi, Oxylabs, and AWMProxy—is a watershed moment in the escalating legal tensions between content platforms and generative AI companies. Much like the Salesforce case, this suit dives deep into the alleged unauthorized use of copyrighted material and circumvention of digital protections in the race to build and commercialize powerful AI models. At stake is not just Reddit’s data or the business practices of Perplexity, but the very question of how human-generated content on public platforms can or should be used in the AI age.
The Allegations: A Data Heist at Industrial Scale
Reddit’s complaint reads like a cybersecurity thriller. The company accuses Perplexity of orchestrating a scheme to illegally acquire Reddit’s copyrighted content—through scraping services like SerpApi and Oxylabs—without permission or license. These services allegedly circumvented both Reddit’s own anti-scraping defenses and Google’s technological access control system, SearchGuard, by disguising bot traffic to appear human.
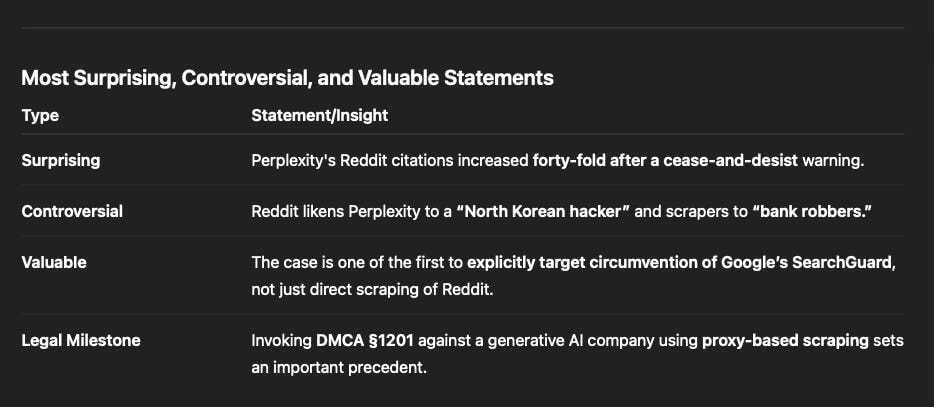
Over a two-week period in July 2025, the data-scraping entities are alleged to have accessed almost three billion search engine results pages (SERPs) containing Reddit content—an industrial-scale operation that Reddit likens to a digital bank heist. Perplexity, the suit alleges, knowingly consumed this illicit data to train and fuel its “answer engine,” increasing Reddit citations forty-fold after being served a cease-and-desist letter.
Legal Claims: DMCA, Trespass, and Willful Circumvention
Reddit’s legal claims center on violations of the Digital Millennium Copyright Act (DMCA), specifically 17 U.S.C. § 1201, which prohibits the circumvention of technological protection measures. The company also alleges trespass to chattels, unjust enrichment, and unfair competition, echoing the arguments it previously raised in its June 2025 lawsuit against Anthropic.
The narrative is one of deliberate evasion: Reddit claims it offered API access under strict licensing terms—terms respected by companies like Google and OpenAI—but Perplexity opted instead for backdoor access using scraping partners who built tools explicitly designed to bypass safeguards. This included the use of residential proxies, CAPTCHA solvers, and masked user agents to impersonate regular human traffic.
Why It Matters: Licensing, AI Ethics, and the “Data Laundering” Economy
This case encapsulates the broader industry crisis around AI training data: as human-generated content becomes the lifeblood of AI systems, ethical boundaries and licensing frameworks are being stress-tested. Reddit’s Chief Legal Officer Ben Lee described the current environment as an “industrial-scale data laundering economy,” where AI firms bypass licensing regimes under the guise of “publicly available data”.
Reddit, by contrast, positions itself as a steward of human discourse and asserts that data scraped—even if technically “public”—cannot be commercially exploited without consent. This distinction could have broad legal consequences, particularly around contractual enforceability of Terms of Service, clickwrap agreements, and robots.txt compliance.
Strength of the Evidence
Reddit claims to have used a digital analog of “marked bills” to trace its data to Perplexity, suggesting deliberate evasion and tracking capabilities capable of confirming misuse. The scale of the scraping, the detailed jurisdictional links to New York, and the inclusion of IP geolocation and corporate ties to scraping vendors all point to a well-prepared and highly detailed complaint. The presence of prior communications—namely the cease-and-desist letter—further supports Reddit’s argument that Perplexity acted willfully.
Moreover, the complaint methodically demonstrates how Reddit’s anti-scraping systems (e.g., CAPTCHA, rate-limiting, and robots.txt) and Google’s SearchGuard were bypassed. These actions could meet the DMCA’s threshold for “circumvention,” bolstering Reddit’s chances of success in court.
Potential Outcomes
Reddit seeks damages and an injunction against further use of its content by Perplexity. If successful, this case could:
Set a legal precedent that circumvention of content platforms’ access controls—even via intermediaries like Google—is unlawful under DMCA §1201.
Force other AI companies to reassess their data supply chains and invest in direct licensing models.
Inspire additional lawsuits from other content platforms, especially those whose Terms of Service and API access models mirror Reddit’s.
Conversely, if Reddit loses, it may signal that public availability through search engines offers a legal loophole for data acquisition—a major blow to content owners attempting to monetize their data in the AI age.
Lessons for Rights Owners, Platforms, and AI Developers
For Rights Owners:
Robust contractual language, active monitoring, and enforcement are essential.
Partnerships with trusted AI companies should include technical guardrails and audit rights.
Legal readiness to pursue bad actors is now part of any data licensing strategy.
For Platforms:
Simply having a Terms of Service and robots.txt file is insufficient—technological enforcement, traceability mechanisms, and forensic tracking are now vital.
Investments in anti-scraping infrastructure pay off not just in prevention but also in litigation success.
For AI Developers:
“Scrape now, apologize later” is a high-risk strategy. Avoiding direct licensing may expose companies to significant legal liability.
Legal interpretations of “public data” are shifting; compliance with data provenance and consent models is increasingly non-negotiable.
Conclusion: The Battle Lines Are Drawn
The Reddit v. Perplexity case is emblematic of a maturing AI ecosystem where the free-for-all era of data scraping may be coming to a close. As platforms like Reddit enforce licensing regimes and courts begin to weigh the legality of training AI on unlicensed content, AI companies face a reckoning: respect content boundaries, or risk reputational and legal fallout.
For now, Reddit’s lawsuit is not just about scraped posts—it’s about reclaiming control over human expression in an AI economy increasingly fueled by it.