- Pascal's Chatbot Q&As
- Posts
- About the Mensch proposal: "A critical oversight in many copyright discussions is the assumption that training data only adds value when the model reproduces content similar to that data."
About the Mensch proposal: "A critical oversight in many copyright discussions is the assumption that training data only adds value when the model reproduces content similar to that data."
However, empirical research in 2025 and 2026 has demonstrated that training data is the fundamental engine of “reasoning” and “emergent abilities” that extend across all model outputs.
Pascal Hetzscholdt
March 22, 2026
Strategic Analysis of Revenue-Based AI Content Levies in the European Intellectual Property Ecosystem
by Gemini 3.0, Deep Research. Warning, LLMs may hallucinate!
The emergence of generative artificial intelligence as a dominant economic force has precipitated a profound structural crisis within the global intellectual property framework. By early 2026, the tension between the voracious data requirements of frontier AI models and the established rights of human creators has transitioned from theoretical legal debate to a high-stakes legislative confrontation. At the center of this transition is a proposal articulated by Arthur Mensch, the Chief Executive Officer of Mistral AI, advocating for the implementation of a mandatory, revenue-based content levy in Europe.1 This proposal seeks to replace the existing, largely voluntary opt-out mechanisms with a systemic compensation fund, ostensibly to provide the legal certainty necessary for European firms to compete with American and Chinese behemoths while offering a sustainable revenue stream for the cultural sector.1
The Mensch Proposal: Mechanical and Strategic Foundations
The proposal put forward by Mistral AI in March 2026 suggests a fundamental reconfiguration of how AI developers interact with the digital commons. The core mechanism is a levy, suggested to be between 1.0% and 1.5% of the annual revenue of commercial AI providers operating within the European market.1 This charge would reflect the developers’ use of publicly available online content for the purpose of model training.1 Unlike individual licensing agreements, which are negotiated on a per-entity basis, this levy would apply to all providers placing AI models on the market or putting them into service in Europe, regardless of their domestic or foreign origin.1
The strategic intent behind this mechanism is twofold. First, it aims to create a “level playing field” by ensuring that foreign AI companies, particularly those from jurisdictions with more permissive copyright rules, contribute to the European cultural ecosystem if they seek to operate within the Union.1 Second, it offers AI developers a “statutory shield” from liability for training on materials accessible online, thereby resolving the persistent legal uncertainty that currently hampers long-term investment and growth.1
Comparative Framework of Current and Proposed Remuneration Models
The proposed levy is positioned as a middle-ground solution between the “wild west” of unlicensed scraping and the prohibitive costs of comprehensive individual licensing. The following table provides a comparison of the Mensch proposal against the current European regulatory environment and other proposed global frameworks.

Historical Precedents and the Legacy of European Levies
The concept of a content levy is not without precedent in European law, drawing inspiration from the long-standing “private copying” levies applied to hardware and storage media. In jurisdictions like Germany, consumers pay a fee on devices such as USB sticks or mass storage devices because these tools enable the creation of private copies of copyrighted songs or films.3 The Mensch proposal seeks to adapt this logic to the scale of artificial intelligence, arguing that since AI models are built upon the totality of human creative output, the developers of these models should pay a systemic fee for the “consumptive use” of that data.6
Furthermore, recent legislative trends in Europe have seen the introduction of reinvestment quotas for digital service providers. Germany’s Investment Obligation Act and Italy’s implementation of the Audiovisual Media Services (AVMS) Directive require streaming platforms to reinvest between 10% and 25% of their locally generated revenue into European audiovisual productions.8 These mandates are framed as cultural policies designed to support domestic industries and are often viewed as “mandatory local content levies” that disproportionately impact non-European platforms.8 The Mistral proposal extends this logic to the AI sector, suggesting that the “central European fund” would reinvest proceeds into new content creation and the broader cultural sector.1
Comparison to the “Consent and Compensation” Framework
The academic community has also explored similar concepts, most notably the “Consent and Compensation” framework developed by Frank Pasquale and Haochen Sun.10 This model grants creators a specific legal right to opt out of AI training while implementing a compensation system for those who do not opt out.10 It relies on emerging technologies to detect whether an AI output was clearly derived from or influenced by a particular artist’s training data, thereby enabling a share of the revenue to be directed back to that artist.10 In contrast, the Mensch proposal appears more systemic and less focused on individual attribution, favoring a centralized fund over direct artist-to-provider transactions.1
Stakeholder Analysis: Assessing the Net Impact
The question of whether a mandatory levy constitutes a net positive or negative for the creative ecosystem requires a multi-faceted analysis of diverse stakeholders, ranging from individual creators and large publishers to AI developers and the public interest.
For individual authors and creators, the levy proposal offers a significant potential benefit: the formalization of a revenue stream where none currently exists. Most individual creators lack the bargaining power to negotiate with AI developers, and their work is currently scraped under the “opt-out” regime, which Mensch describes as unworkable and overly complex.1 A central fund could provide a mechanism for these creators to benefit from the overall success of the AI economy without the need for individual litigation or negotiation.
However, the proposal is also viewed with significant skepticism. The primary concern is “institutional capture,” where the proceeds of the levy flow into a central fund and are distributed to large cultural institutions or “cultural sectors” rather than the specific individuals whose data was used to train the models.1 Some creators have characterized the proposal as a “screwing” of the individual artist, as they lose the ability to exclude their work from training while receiving no guarantee of direct compensation.1 Furthermore, critics like Neil Turkewitz argue that AI training is a “thoroughly consumptive use” that might erase the entire value of the underlying work.7 In this view, a 1% levy is an inadequate substitute for the “exclusive right” to authorize or prohibit use, effectively relegating copyright to a protection of the past rather than a tool for future empowerment.7
Rights Owners and Publishers: Preservation of High-Value Markets
For large publishers and rights owners, the levy represents a baseline for compensation. Mensch emphasizes that the levy would not replace licensing agreements or the freedom to contract for “usage beyond training”.1 This dual-track approach allows publishers to receive a steady stream of income from the levy while still pursuing lucrative direct deals for specialized data sets or high-quality archives.1
Conversely, the mandatory nature of the levy could undermine the bargaining power of major publishers. If a statutory shield is granted in exchange for the levy, publishers lose their primary leverage: the threat of copyright litigation for unlicensed training.1 Furthermore, the administrative complexity of managing a central fund and ensuring fair distribution across millions of works could lead to significant overhead and inefficiencies.6
AI Developers and Startups: Legal Certainty vs. Operational Costs
For AI developers, the primary advantage of the levy is “legal certainty”.1 The current legal landscape is characterized by high-stakes litigation, such as the New York Times v. OpenAI and Getty v. Stability AI cases, which threaten the very foundations of the generative AI industry.11 By paying a predictable percentage of revenue, companies like Mistral can insulate themselves from the risk of ruinous damages or injunctions.1
However, for early-stage startups, a 1% to 1.5% revenue levy could be a significant burden, particularly as the costs of compute, talent, and data are already escalating.5 Critics also argue that a levy might lead to “market failure” by creating an additional layer of regulation that makes European AI products less competitive against those from jurisdictions with no such mandates.3
The Economic Calculus: Litigation Risk vs. Comprehensive Licensing
The decision by AI companies to risk litigation rather than paying for all training data in full is rooted in a stark economic reality: the cost of comprehensive licensing is considered “astronomical” [User Query]. The global AI training dataset sector is projected to reach $9.58 billion by 2029, with publishers increasingly shifting from free scraping to paid models.5
The Cost of Comprehensive Licensing
Individual licensing costs are prohibitive for the volume of data required to train a frontier model. Modern LLMs are trained on trillions of tokens, encompassing millions of books, articles, and artistic works.6 As an example of current market benchmarks, HarperCollins reportedly charges $5,000 per title for three-year AI training rights.5

If a model requires 1,000,000 high-quality books to achieve a reasoning threshold, the cost at current benchmarks would be:
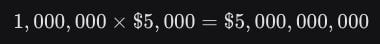
This $5 billion price tag for books alone exceeds the total venture capital raised by most AI startups. Mistral itself, a leader in the European market, secured €1.7 billion in September 2025, which would cover only a fraction of a fully licensed dataset.15
The Litigation and Settlement Landscape
In contrast to the certainty of a multi-billion dollar licensing bill, many AI companies choose the “litigation risk” path. This involves training on scraped data and setting aside funds for legal defense and potential settlements. The following table summarizes the financial implications of this strategy as of late 2025 and 2026.

The strategy of “risk and settle” appears more economically viable than full up-front licensing, provided the companies can survive the initial wave of lawsuits. However, the Mensch proposal argues that this constant threat of litigation hampers investment and favors deep-pocketed “Big Tech” firms that can afford $1.5 billion settlements, thereby entrenching a “dangerous concentration of power” in the AI sector.19
The Multi-Dimensional Value of Training Data: Beyond Output to Intelligence
A critical oversight in many copyright discussions is the assumption that training data only adds value when the model reproduces content similar to that data. However, empirical research in 2025 and 2026 has demonstrated that training data is the fundamental engine of “reasoning” and “emergent abilities” that extend across all model outputs.20
Foundational Capabilities and reasoning Injection
Research into the training dynamics of large language models (LLMs) has revealed that the “front-loading” of high-quality reasoning data during the pretraining phase is critical for establishing a “durable foundational ceiling” for the model.21 A systematic study found that models pre-trained with reasoning-intensive data (such as mathematical proofs or logical chain-of-thought traces) saw an average gain of 19% in overall performance.21
This gain is not merely additive; it is compounding. The injection of reasoning data early in the pipeline establishes foundational capabilities that cannot be fully replicated or “recovered” by later-stage supervised fine-tuning (SFT), even if massive amounts of data are used at that stage.21 High-quality pretraining data has “latent effects” that are only activated after the model undergoes alignment, revealing a deep synergy where early data volume prepares the model to better absorb instruction later.21
Emergent Abilities and the Scaling Law Threshold
The value of training data is also tied to the phenomenon of “emergence.” Scaling laws establish a relationship between model parameters, training compute, and dataset size.20 While most performance improvements follow predictable curves, certain “emergent abilities”—ranging from advanced coding to symbolic reasoning—only appear after a model reaches a “critical scale threshold”.20

Commercial and Functional Value Drivers
Beyond output and reasoning, training data contributes to the commercial performance of a model in several distinct ways:
Pattern Recognition and Accuracy: Larger datasets allow models to become more precise at identifying textual and semantic patterns, leading to higher accuracy in factual retrieval.24
Multilingual Autonomy: Training on diverse European sources is essential for preserving “digital sovereignty” and ensuring that models reflect local cultural values and linguistic nuances rather than a generic, US-centric worldview.1
Task Versatility: Through “self-supervision at scale,” models develop general-purpose capabilities that allow them to perform functions entirely different from the original intent of the training data, such as converting literary works into structured code.24
Sovereign Infrastructure: Investing in data as a “common good” allows for the creation of public foundation models that remain open-source and democratically governed, preventing the “data winter” where proprietary actors secure exclusive access to information.4
Market Projections and the Levy’s Economic Footprint
The implementation of a 1.5% levy on the European AI market would have a significant financial impact. The AI market in Europe is currently experiencing rapid growth, driven by the adoption of generative AI across sectors like healthcare, finance, and manufacturing.17
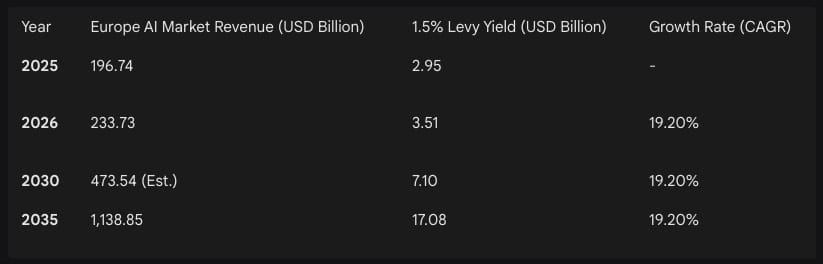
The yield from such a levy—over $3.5 billion in 2026 alone—would create one of the largest cultural funds in the world.17 For comparison, the entire European Commission allocation for digital innovation under the Horizon Europe Work Programme for 2026 is approximately €307.3 million ($334 million).18 The levy would thus provide a funding source for the cultural sector that is nearly ten times larger than existing public innovation subsidies.
Challenges to Implementation and Industry Criticism
Despite the potential benefits of the levy, the proposal faces significant hurdles, both legal and economic. Critics within the industry and the legal profession have identified several critical points of failure.
Conflict with International Copyright Treaties
Legal experts like Neil Turkewitz argue that mandatory levies may conflict with international laws such as the Berne Convention and the WTO TRIPS Agreement.7 These treaties prohibit “formalities” like mandatory opt-outs and restricted licensing if they conflict with the “normal exploitation of the work”.7 Since AI training is now a “central economic activity” rather than a secondary or ancillary one, a flat-rate levy may be seen as a violation of the rights holders’ exclusive right to authorize use.7
Inflexibility and Administrative Complexity
Levies are often described as “too cumbersome and inflexible” to respond to a rapidly changing marketplace.7 Unlike a dynamic licensing market where prices can adjust based on the value of specific data, a flat percentage levy may undercompensate owners of high-value data while overcompensating others.7 Furthermore, the creation of a “central European fund” introduces a new layer of bureaucracy, with concerns about how funds will be allocated and whether they will effectively reach individual creators.1
Protectionism and Trade Barriers
Organizations like the Computer & Communications Industry Association (CCIA) view mandatory reinvestment obligations and local content levies as “discriminatory trade barriers” that disproportionately target U.S. technology firms.8 These measures are seen as attempts to force American companies to subsidize European domestic industries, which could lead to retaliatory trade actions or a “regulatory fragmentation” that discourages investment in the European market.8
Conclusions and Strategic Outlook
The proposal by Mistral CEO Arthur Mensch for a revenue-based AI content levy represents a pivotal attempt to resolve the fundamental “property vs. technology” conflict that defines the early 21st-century economy. The analysis demonstrates that the current “opt-out” framework is viewed as insufficient by both the creative sector, which feels uncompensated, and the technology sector, which feels legally exposed.1
The mandatory levy offers a pragmatic “third way” that avoids the binary choice between the astronomical cost of full licensing and the perpetual risk of litigation.1 For authors and creators, the levy is a potential net positive if—and only if—the distribution mechanism is transparent and prevents the capture of funds by large institutional intermediaries.1 For AI developers, the levy provides the “legal certainty” essential for competing at the global frontier of intelligence.1
Ultimately, the value of training data is found not in the reproduction of content, but in the creation of generalized intelligence. The 19% gain in model performance derived from reasoning data and the triggering of emergent abilities through scale make data the most vital infrastructure of the AI age.20 As Europe seeks to become an “ethical AI leader,” the implementation of a content levy could serve as a global model for a “new deal” between creators and the digital frontier, provided it can navigate the complexities of international law and the competitive pressures of a global market.4
Works cited
Mistral CEO: AI companies should pay a content levy in Europe, accessed March 22, 2026
AI model giants should pay a levy to operate in Europe, says Mistral boss - Tech.eu, accessed March 22, 2026, https://tech.eu/2026/03/20/ai-model-giants-should-pay-a-levy-to-operate-in-europe-says-mistral-boss/
Mistral CEO: AI companies should pay a content levy in Europe : r/LocalLLaMA - Reddit, accessed March 22, 2026, https://www.reddit.com/r/LocalLLaMA/comments/1rzds1b/mistral_ceo_ai_companies_should_pay_a_content/
Copyright, AI, and the Limits of Voluntary Licensing – Open Future, accessed March 22, 2026, https://openfuture.eu/blog/copyright-ai-and-the-limits-of-voluntary-licensing/
AI Startup Training Data Costs Skyrocket After Lawsuit. - USTechTimes, accessed March 22, 2026, https://ustechtimes.com/unlicensed-training-data-threatens-enterprise-contracts-and-funding-for-ai-startups/
VOLUME 14, NUMBER 1, 2025, accessed March 22, 2026, https://www.unipo.sk/sites/default/files/content/84235/04_asp_2025_1_madera.pdf
Consent and Compensation: Resolving Generative AI’s Copyright ..., accessed March 22, 2026, https://medium.com/@nturkewitz_56674/copyright-2023-neil-turkewitz-2bf3772e0114
2025 Digital Trade Barriers in the EU - CCIA, accessed March 22, 2026, https://ccianet.org/wp-content/uploads/2025/10/2025-Digital-Trade-Barriers-in-the-EU.pdf
ALTERNATIVE BUDGET 2026 - The Labour Party, accessed March 22, 2026, https://labour.ie/wp-content/uploads/2025/10/Labour-Alternative-Budget-2026.pdf
Copyright Law in the Age of AI: Navigating Authorship, Infringement ..., accessed March 22, 2026, https://nysba.org/copyright-law-in-the-age-of-ai-navigating-authorship-infringement-and-creative-rights/
2026 AI Legal Forecast: From Innovation to Compliance | Baker ..., accessed March 22, 2026, https://www.bakerdonelson.com/2026-ai-legal-forecast-from-innovation-to-compliance
AI Trends for 2026 - Copyright Litigation Shifts from Training Data to AI Outputs, accessed March 22, 2026, https://www.mofo.com/resources/insights/260210-ai-trends-for-2026-copyright-litigation
AI Pricing: What’s the True AI Cost for Businesses in 2026? - Zylo, accessed March 22, 2026, https://zylo.com/blog/ai-cost/
Generative AI Tools for Collaborative Content Creation - R Discovery, accessed March 22, 2026, https://discovery.researcher.life/article/generative-ai-tools-for-collaborative-content-creation/2abacb4b99403358819dc542e818ef87
Europe Artificial Intelligence Market Size and Report 2034 - IMARC Group, accessed March 22, 2026, https://www.imarcgroup.com/europe-artificial-intelligence-market
Analysis of the NYT vs OpenAI/Microsoft lawsuit, by an actual lawyer and not just someone who thinks they are one. - Reddit, accessed March 22, 2026, https://www.reddit.com/r/singularity/comments/18tjhv5/analysis_of_the_nyt_vs_openaimicrosoft_lawsuit_by/
Europe Artificial Intelligence Market Size, Share and Trends 2026 to 2035, accessed March 22, 2026, https://www.precedenceresearch.com/europe-artificial-intelligence-market
Europe Artificial Intelligence Market Size, Share and Trends 2026 to 2035 | BIIA.com, accessed March 22, 2026, https://www.biia.com/europe-artificial-intelligence-market-size-share-and-trends-2026-to-2035/
Mistral AI’s Arthur Mensch Warns Against AI Power Concentration at India AI Summit, accessed March 22, 2026, https://www.frenchtechjournal.com/mistral-ais-arthur-mensch-warns-against-ai-power-concentration-at-india-ai-summit/
Emergent Abilities in Large Language Models: A Survey, accessed March 22, 2026, https://arxiv.org/abs/2503.05788
Front-Loading Reasoning: The Synergy between Pretraining ... - arXiv, accessed March 22, 2026, https://arxiv.org/abs/2510.03264
Emergent Abilities of Large Language Models - Jason Wei,Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud,, accessed March 22, 2026, https://www.cs.toronto.edu/~cmaddis/courses/csc2541_w25/presentations/dash_emergence.pdf
Emergent Abilities in Large Language Models: A Survey - arXiv, accessed March 22, 2026, https://arxiv.org/html/2503.05788v2
(PDF) Technical, legal, and ethical challenges of generative artificial ..., accessed March 22, 2026, https://www.researchgate.net/publication/394189563_Technical_legal_and_ethical_challenges_of_generative_artificial_intelligence_an_analysis_of_the_governance_of_training_data_and_copyrights
Mistral AI’s Arthur Mensch makes pitch for Open-Source sovereignty at India AI Impact Summit 2026, accessed March 22, 2026, https://www.fortuneindia.com/business-news/mistral-ais-arthur-mensch-makes-pitch-for-open-source-sovereignty-at-india-ai-impact-summit-2026/130561
Europe’s 2026 Tech Spend Exceeds €1.5 Trillion Driven By AI, Cloud, And Sovereignty, accessed March 22, 2026, https://www.forrester.com/blogs/europes-2026-tech-spend-exceeds-e1-5-trillion-driven-by-ai-cloud-and-sovereignty/
